

Dẫn luận về Dữ liệu lớn (Big Data)- phần 1




Lời nói đầu
Sách về dữ liệu lớn có xu hướng rơi vào một trong hai loại: hoặc chúng không đưa ra lời giải thích về cách mọi thứ thực sự hoạt động hoặc chúng là sách giáo khoa toán học cao cấp, chỉ phù hợp với sinh viên đã tốt nghiệp. Mục đích của cuốn sách này là cung cấp một giải pháp thay thế bằng cách giới thiệu về cách dữ liệu lớn hoạt động và đang thay đổi thế giới, về chúng ta; ảnh hưởng của nó đối với cuộc sống hàng ngày của chúng ta; và ảnh hưởng của nó trong thế giới kinh doanh.
Dữ liệu từng có nghĩa là tài liệu và giấy tờ, có thể với một vài bức ảnh, nhưng bây giờ nó có ý nghĩa nhiều hơn thế. Các trang mạng xã hội tạo ra một lượng lớn dữ liệu dưới dạng hình ảnh, video và phim trên từng phút. Mua sắm trực tuyến tạo dữ liệu khi chúng ta nhập địa chỉ và chi tiết thẻ tín dụng của mình. Bây giờ chúng ta đang ở thời điểm mà việc thu thập và lưu trữ dữ liệu đang phát triển với tốc độ không thể tưởng tượng được so với chỉ vài thập kỷ trước, nhưng, như chúng ta sẽ thấy trong cuốn sách này, các kỹ thuật phân tích dữ liệu mới đang chuyển đổi dữ liệu này thành thông tin hữu ích. Trong khi viết cuốn sách này, tôi thấy rằng dữ liệu lớn không thể được thảo luận một cách có ý nghĩa mà không thường xuyên tham khảo việc thu thập, lưu trữ, phân tích và sử dụng nó bởi những người hoạt động thương mại lớn. Vì các bộ phận nghiên cứu trong các công ty như Google và Amazon chịu trách nhiệm cho nhiều phát triển mạnh trong dữ liệu lớn, nên sẽ thường xuyên tham khảo chúng.
Chương đầu tiên giới thiệu cho người đọc về sự đa dạng của dữ liệu nói chung trước khi giải thích thời đại kỹ thuật số đã dẫn đến những thay đổi trong cách chúng ta định nghĩa dữ liệu như thế nào. Dữ liệu lớn được giới thiệu không chính thức thông qua ý tưởng về sự bùng nổ dữ liệu, liên quan đến khoa học máy tính, thống kê và giao diện giữa chúng. Trong Chương 2 đến Chương 4, tôi đã sử dụng sơ đồ một cách khá rộng rãi để giúp giải thích một số phương pháp mới theo yêu cầu của dữ liệu lớn. Chương hai khám phá những gì làm cho dữ liệu lớn trở nên đặc biệt và, khi làm như vậy, dẫn chúng ta đến một định nghĩa cụ thể hơn. Trong Chương 3, chúng ta thảo luận về các vấn đề liên quan đến lưu trữ và quản lý dữ liệu lớn. Hầu hết mọi người đều quen thuộc với nhu cầu sao lưu dữ liệu trên máy tính cá nhân của họ. Nhưng làm thế nào để chúng ta làm điều này với lượng dữ liệu khổng lồ hiện đang được tạo ra? Để trả lời câu hỏi này, chúng ta sẽ xem xét lưu trữ cơ sở dữ liệu và ý tưởng phân phối các tác vụ trên các cụm máy tính. Chương 4 lập luận rằng dữ liệu lớn chỉ hữu ích nếu chúng ta có thể trích xuất thông tin hữu ích từ nó. Một biểu hiện của cách dữ liệu được chuyển thành thông tin được đưa ra bằng cách sử dụng các giải thích đơn giản của một số kỹ thuật được thiết lập tốt.
Sau đó, chúng ta chuyển sang thảo luận chi tiết hơn về các ứng dụng dữ liệu lớn, bắt đầu từ Chương 5 với vai trò của dữ liệu lớn trong y học. Chương 6 phân tích thực tiễn kinh doanh với các nghiên cứu điển hình trên Amazon và Netflix, mỗi nghiên cứu nêu bật các tính năng khác nhau của tiếp thị bằng cách sử dụng dữ liệu lớn. Chương 7 xem xét một số vấn đề bảo mật xung quanh dữ liệu lớn và tầm quan trọng của mã hóa. Đánh cắp dữ liệu đã trở thành một vấn đề lớn và chúng tôi xem xét một số trường hợp đã được đưa tin bao gồm Snowden và WikiLeaks. Chương này kết thúc bằng cách chỉ ra tội phạm mạng là một vấn đề mà dữ liệu lớn cần giải quyết như thế nào. Trong chương cuối cùng, Chương 8, chúng ta xem xét dữ liệu lớn đang thay đổi xã hội chúng ta đang sống như thế nào, thông qua sự phát triển của các robot tinh vi và vai trò của chúng tại nơi làm việc. Việc xem xét các ngôi nhà thông minh và thành phố thông minh của tương lai kết thúc cuốn sách.
Trong một dẫ luận ngắn không thể đề cập đến tất cả mọi thứ, vì vậy tôi hy vọng người đọc sẽ theo đuổi sở thích của mình thông qua các khuyến nghị của phần Đọc thêm.
Chương 1
Sự bùng nổ dữ liệu
Dữ liệu là gì?
Năm 431 TCN, Sparta tuyên chiến với Athens. Thucydides, trong thuật lại của mình về cuộc chiến, mô tả cách các lực lượng Plataean bị bao vây, trung thành với Athens, đã lên kế hoạch trốn thoát bằng cách leo qua bức tường bao quanh Plataea được xây dựng bởi lực lượng Peloponnesian do Sparta lãnh đạo. Để làm điều này, họ cần biết bức tường cao bao nhiêu để họ có thể làm thang có chiều dài phù hợp. Phần lớn bức tường Peloponnesian được bao phủ bởi đá sỏi thô, nhưng một đoạn đã được tìm thấy, nơi những viên gạch có thể nhìn thấy rõ ràng, và một số lượng lớn binh lính được giao nhiệm vụ đếm các lớp của những viên gạch lộ ra này. Làm việc này ở khoảng cách đủ an toàn ngoài sự tấn công của kẻ thù chắc chắn sẽ gây ra những sai lầm, nhưng như Thucydides giải thích, do nhiều lần đếm đã được thực hiện, kết quả xuất hiện thường xuyên nhất sẽ là chính xác nhất. Số lượng xuất hiện thường xuyên nhất này, mà bây giờ chúng ta sẽ gọi là phương thức (mode), sau đó được sử dụng để tính toán chiều cao của bức tường, người Plataeans biết kích thước của những viên gạch địa phương được sử dụng và thang có chiều dài cần thiết để vượt qua bức tường đã được chế. Điều này cho phép một lực lượng vài trăm người trốn thoát, và sự kiện này có thể được coi là ví dụ ấn tượng nhất về thu thập và phân tích dữ liệu lịch sử. Nhưng việc thu thập, lưu trữ và phân tích dữ liệu thậm chí có trước cả Thucydides nhiều thế kỷ, như chúng ta sẽ thấy.
Các vết đánh dấu (notch) đã được tìm thấy trên gậy, đá và xương có niên đại sớm nhất là thời kỳ đồ đá cũ. Những rãnh này được cho là đại diện cho dữ liệu được lưu trữ dưới dạng dấu kiểm đếm, mặc dù điều này vẫn còn mở ra cho các cuộc tranh luận học thuật. Có lẽ ví dụ nổi tiếng nhất là Xương Ishango, được tìm thấy ở Cộng hòa Dân chủ Congo vào năm 1950, và ước tính khoảng 20.000 năm tuổi. Xương có đánh dấu này đã được hiểu khác nhau, như một máy tính hoặc lịch, mặc dù những người khác thích giải thích các vết dạng rãnh ở đó chỉ để cung cấp độ bám tốt hơn. Xương Lebombo, được phát hiện vào những năm 1970 ở Swaziland, thậm chí còn lâu đời hơn, có niên đại khoảng 35.000 năm trước Công nguyên. Với hai mươi chín vết đánh dấu được ghi trên đó, mảnh xương của khỉ đầu chó này có sự tương đồng nổi bật với những cây gậy lịch vẫn được sử dụng bởi những người đi rừng ở Namibia xa xôi, cho thấy đây thực sự có thể là một phương pháp được sử dụng để theo dõi dữ liệu quan trọng đối với nền văn minh của họ.
Trong khi việc giải thích các xương có vết này vẫn còn bỏ ngỏ để suy đoán, chúng ta biết rằng một trong những cách sử dụng dữ liệu được ghi chép đầy đủ đầu tiên là cuộc điều tra dân số được thực hiện bởi người Babylon vào năm 3800 trước Công nguyên. Cuộc điều tra dân số này ghi lại một cách có hệ thống số lượng dân số và hàng hóa, chẳng hạn như sữa và mật ong, để cung cấp thông tin cần thiết cho việc tính thuế. Người Ai Cập, đầu tiên cũng sử dụng dữ liệu, dưới dạng chữ tượng hình được viết trên gỗ hoặc giấy cói, để ghi lại việc giao hàng và theo dõi thuế. Nhưng các ví dụ ban đầu về việc sử dụng dữ liệu không chỉ giới hạn ở châu Âu và châu Phi. Người Inca và những người tiền sử Nam Mỹ của họ, muốn ghi lại số liệu thống kê cho mục đích thuế và thương mại, đã sử dụng một hệ thống dây thắt nút màu tinh vi và phức tạp, được gọi là quipu, như một hệ thống kế toán dựa trên thập phân. Những sợi dây thắt nút này, được làm từ bông nhuộm sáng hoặc len lạc đà, có từ thiên niên kỷ thứ ba trước Công nguyên, và mặc dù chỉ còn dưới một nghìn, sót lại sau cuộc xâm lược của Tây Ban Nha và nỗ lực sau đó phá huỷ chúng, đây là một trong những ví dụ đầu tiên được biết đến về một hệ thống lưu trữ dữ liệu khổng lồ. Các thuật toán máy tính hiện đang được phát triển để cố gắng giải mã ý nghĩa đầy đủ của quipu và nâng cao hiểu biết của chúng ta về cách chúng được sử dụng.
Mặc dù chúng ta có thể cho rằng và mô tả các hệ thống ban đầu này bằng cách sử dụng “dữ liệu”, từ ‘data‘ thực sự là một từ số nhiều có nguồn gốc Latinh, với ‘datum‘ là số ít. ‘Datum’ hiếm khi được sử dụng ngày nay và “dữ liệu” được sử dụng cho cả số ít và số nhiều. Từ điển tiếng Anh Oxford cho rằng, việc sử dụng thuật ngữ này lần đầu tiên được biết đến là do giáo sĩ người Anh thế kỷ 17, Henry Hammond, trong một bài báo tôn giáo gây tranh cãi xuất bản năm 1648. Trong đó, Hammond đã sử dụng cụm từ ‘đống dữ liệu’, theo nghĩa thần học, để chỉ những sự thật tôn giáo không thể chối cãi. Nhưng mặc dù ấn phẩm này nổi bật là đại diện cho lần đầu tiên sử dụng thuật ngữ ‘dữ liệu’ trong tiếng Anh, nó không nắm bắt được việc sử dụng nó theo nghĩa hiện đại để biểu thị các sự kiện và số liệu về sự quan tâm phổ biến. ‘Dữ liệu’, như chúng ta hiểu ngày nay, có nguồn gốc từ cuộc cách mạng khoa học vào thế kỷ 18 do những người khổng lồ trí tuệ như Priestley, Newton và Lavoisier lãnh đạo; và, đến năm 1809, sau công trình của các nhà toán học trước đó, Gauss và Laplace đã đặt nền móng toán học cao cho phương pháp thống kê hiện đại.
Ở mức độ thực tế hơn, một lượng lớn dữ liệu đã được thu thập về vụ dịch tả bùng phát năm 1854 ở Broad Street, London, cho phép bác sĩ John Snow lập biểu đồ lây nhiễm. Bằng cách đó, ông đã có thể hỗ trợ cho giả thuyết của mình rằng nước bị ô nhiễm lây lan căn bệnh này và cho thấy rằng nó không lây lan trong không khí như đã được tin trước đây. Thu thập dữ liệu từ người dân địa phương, ông xác định rằng những người bị ảnh hưởng đều sử dụng cùng một máy bơm nước công cộng; Sau đó, ông thuyết phục chính quyền giáo xứ địa phương đóng cửa chỗ đó, một nhiệm vụ mà họ đã hoàn thành bằng cách tháo tay cầm máy bơm. Snow sau đó đã tạo ra một bản đồ, bây giờ đã nổi tiếng, cho thấy cách căn bệnh này đã lan ra trong các cụm xung quanh máy bơm Broad Street. Ông tiếp tục làm việc trong lĩnh vực này, thu thập và phân tích dữ liệu, và nổi tiếng là một nhà dịch tễ học tiên phong.
Sau công trình của John Snow, các nhà dịch tễ học và các nhà khoa học xã hội ngày càng tìm thấy dữ liệu nhân khẩu học vô giá cho mục đích nghiên cứu và cuộc điều tra kiểm đếm (census) hiện được thực hiện ở nhiều quốc gia chứng minh đó là một nguồn thông tin hữu ích. Ví dụ, dữ liệu về tỷ lệ sinh và chết, tần suất của các bệnh khác nhau và số liệu thống kê về thu nhập và tội phạm hiện được thu thập, điều này đã không xảy ra trước thế kỷ 19. Các cuộc điều tra dân số, diễn ra mười năm một lần ở hầu hết các quốc gia, đã thu thập lượng dữ liệu ngày càng tăng, cuối cùng dẫn đến nhiều hơn những gì có thể được ghi lại thực tế bằng tay hoặc các máy kiểm đếm đơn giản được sử dụng trước đây. Thách thức của việc xử lý số lượng dữ liệu điều tra kiểm đếm ngày càng tăng này đã được Herman Hollerith đáp ứng một phần khi làm việc cho Cục điều tra kiểm đếm Hoa Kỳ (US Census Bureau).
Theo bộ phận kiểm đếm Hoa Kỳ, cho đến năm 1870, một máy kiểm đếm đơn giản đã hoạt động nhưng điều này không thành công trong việc giảm công việc của Cục điều tra kiểm đếm. Một bước đột phá đã đến đúng lúc cho điều tra kiểm đếm năm 1890, khi máy lập bảng thẻ đục lỗ của Herman Hollerith, dùng để lưu trữ và xử lý dữ liệu, được sử dụng. Thời gian cần thiết để xử lý dữ liệu điều tra kiểm đếm Hoa Kỳ thường là khoảng tám năm, nhưng sử dụng phát minh mới này, thời gian đã giảm xuống còn một năm. Cỗ máy của Hollerith đã cách mạng hóa việc phân tích dữ liệu điều tra kiểm đếm ở các quốc gia trên toàn thế giới, bao gồm Đức, Nga, Na Uy và Cuba.
Hollerith sau đó đã bán máy của mình cho công ty, mà sau phát triển thành IBM, sau đó phát triển và sản xuất một loạt máy thẻ đục lỗ được sử dụng rộng rãi. Năm 1969, Viện Tiêu chuẩn Quốc gia Hoa Kỳ (ANSI) đã xác định Mã thẻ đục lỗ Hollerith (hoặc Mã thẻ Hollerith), tôn vinh Hollerith vì phát kiến thẻ đục lỗ ban đầu của ông.
Dữ liệu trong thời đại kỹ thuật số
Trước khi sử dụng rộng rãi máy tính, dữ liệu từ cuộc điều tra kiểm đếm, thí nghiệm khoa học hoặc khảo sát mẫu và bảng câu hỏi được thiết kế cẩn thận, đã được ghi lại trên giấy – một quá trình tốn thời gian và tốn kém. Việc thu thập dữ liệu chỉ có thể diễn ra khi các nhà nghiên cứu đã quyết định những câu hỏi nào họ muốn thí nghiệm hoặc khảo sát của họ trả lời, và dữ liệu có cấu trúc cao, được sao chép trên giấy theo các hàng và cột có thứ tự, sau đó có thể đưa vào các phương pháp phân tích thống kê truyền thống. Đến nửa đầu thế kỷ 20, một số dữ liệu đã được lưu trữ trên máy tính, giúp giảm bớt một số công việc tốn nhiều công sức này, nhưng thông qua sự ra mắt của World Wide Web (hoặc Web) vào năm 1989 và sự phát triển nhanh chóng của nó, việc tạo, thu thập, lưu trữ và phân tích dữ liệu bằng điện tử ngày càng trở nên khả thi. Các vấn đề chắc chắn được tạo ra bởi khối lượng dữ liệu rất lớn mà Web có thể truy cập được sau đó cần được giải quyết và trước tiên chúng ta xem xét cách chúng ta có thể phân biệt giữa các loại dữ liệu khác nhau.
Dữ liệu chúng ta lấy từ Web có thể được phân loại là có cấu trúc, không có cấu trúc hoặc bán cấu trúc.
Dữ liệu có cấu trúc, thuộc loại được viết bằng tay và được lưu giữ trong sổ ghi chép hoặc trong tủ hồ sơ, hiện được lưu trữ điện tử trên bảng tính hoặc cơ sở dữ liệu, và bao gồm các bảng kiểu bảng tính với các hàng và cột, mỗi hàng là một bản ghi và mỗi cột là một trường được xác định rõ (ví dụ: tên, địa chỉ và tuổi). Chúng ta đang đóng góp vào các kho dữ liệu có cấu trúc này khi, ví dụ, chúng ta cung cấp thông tin cần thiết để đặt hàng trực tuyến. Dữ liệu được cấu trúc và lập bảng cẩn thận, tương đối dễ quản lý và có thể đi vào phân tích thống kê, thực sự cho đến gần đây các phương pháp phân tích thống kê chỉ có thể được áp dụng cho dữ liệu có cấu trúc.
Ngược lại, dữ liệu phi cấu trúc không dễ phân loại, bao gồm ảnh, video, thông điệp ngắn/tweet và tài liệu xử lý văn bản. Khi việc sử dụng World Wide Web trở nên phổ biến, nhiều nguồn thông tin tiềm năng như vậy vẫn không thể truy cập được vì chúng thiếu cấu trúc cần thiết cho các kỹ thuật phân tích hiện có được áp dụng. Tuy nhiên, bằng cách xác định các tính năng chính, dữ liệu xuất hiện ngay từ cái nhìn đầu tiên là không có cấu trúc có thể không hoàn toàn là không có cấu trúc. Ví dụ: email chứa siêu dữ liệu có cấu trúc trong tiêu đề cũng như thông điệp phi cấu trúc thực tế trong văn bản và do đó có thể được phân loại là dữ liệu bán cấu trúc. Thẻ siêu dữ liệu, về cơ bản là các tham chiếu mô tả, có thể được sử dụng để thêm một số cấu trúc vào dữ liệu phi cấu trúc. Thêm thẻ từ vào hình ảnh trên trang web làm cho nó có thể nhận dạng được và dễ tìm kiếm hơn. Dữ liệu bán cấu trúc cũng được tìm thấy trên các trang mạng xã hội, sử dụng hashtag để có thể xác định được thông điệp (là dữ liệu phi cấu trúc) về một chủ đề cụ thể. Xử lý dữ liệu phi cấu trúc là một thách thức: vì nó không thể được lưu trữ trong cơ sở dữ liệu hoặc bảng tính truyền thống, các công cụ đặc biệt đã phải được phát triển để trích xuất thông tin hữu ích. Trong các chương sau, chúng ta sẽ xem xét cách dữ liệu phi cấu trúc được lưu trữ.
Thuật ngữ ‘bùng nổ dữ liệu’, ở đầu chương này, đề cập đến số lượng ngày càng lớn dữ liệu có cấu trúc, không có cấu trúc và bán cấu trúc được tạo ra từng phút. Tiếp theo chúng ta sẽ xem xét một số trong nhiều nguồn khác nhau tạo ra tất cả dữ liệu này.
Giới thiệu về dữ liệu lớn
Chỉ mới vào quá trình nghiên cứu tài liệu cho cuốn sách này, tôi đã bị tràn ngập bởi khối lượng dữ liệu khổng lồ có sẵn trên Web – từ các trang web, tạp chí khoa học và sách giáo khoa điện tử. Theo một nghiên cứu trên toàn thế giới gần đây được thực hiện bởi IBM, khoảng 2,5 exabyte (Eb) dữ liệu được tạo ra mỗi ngày. Một Eb là 1018 (1 theo sau là mười tám số 0) byte (hoặc một triệu terabyte (Tb); xem biểu đồ kích thước byte dữ liệu lớn ở cuối cuốn sách này). Một máy tính xách tay tốt được mua tại thời điểm viết bài thường sẽ có ổ cứng với 1 hoặc 2 Tb dung lượng lưu trữ. Ban đầu, thuật ngữ ‘dữ liệu lớn’ chỉ đơn giản đề cập đến lượng dữ liệu rất lớn được tạo ra trong thời đại kỹ thuật số. Những lượng dữ liệu khổng lồ này, cả có cấu trúc và không có cấu trúc, bao gồm tất cả dữ liệu Web được tạo ra bởi email, trang web và các trang web mạng xã hội.
Khoảng 80% dữ liệu của thế giới là phi cấu trúc dưới dạng văn bản, hình ảnh và hình vẽ, và do đó nó không thể tuân theo các phương pháp phân tích dữ liệu có cấu trúc truyền thống. ‘Dữ liệu lớn’ hiện được sử dụng để chỉ không chỉ tổng lượng dữ liệu được tạo và lưu trữ điện tử, mà còn đề cập đến các bộ dữ liệu cụ thể lớn cả về kích thước và độ phức tạp, trong đó các kỹ thuật thuật toán mới được yêu cầu để trích xuất thông tin hữu ích từ chúng. Những bộ dữ liệu lớn này đến từ các nguồn khác nhau, vì vậy chúng ta hãy xem xét chi tiết hơn về một số trong số chúng và dữ liệu mà chúng tạo ra.
Dữ liệu công cụ tìm kiếm
Năm 2015, Google là công cụ tìm kiếm phổ biến nhất trên toàn thế giới, với Bing của Microsoft và Yahoo Search lần lượt đứng thứ hai và thứ ba. Trong năm 2012, năm gần đây nhất mà dữ liệu được công khai, đã có hơn 3,5 tỷ tìm kiếm được thực hiện mỗi ngày chỉ riêng trên Google.
Nhập một thuật ngữ chính vào công cụ tìm kiếm sẽ tạo ra một danh sách các trang web có liên quan nhất, nhưng đồng thời một lượng dữ liệu đáng kể đang được thu thập. Theo dõi web tạo ra dữ liệu lớn. Như một bài tập, tôi đã tìm kiếm trên ‘border collies’ và nhấp vào trang web hàng đầu được trả lại. Sử dụng một số phần mềm theo dõi cơ bản, tôi thấy rằng khoảng sáu mươi bảy kết nối trang web của bên thứ ba đã được tạo chỉ bằng cách nhấp vào một trang web này. Để theo dõi sự quan tâm của những người truy cập web, thông tin đang được chia sẻ theo cách này giữa các doanh nghiệp thương mại.
Mỗi khi chúng ta sử dụng công cụ tìm kiếm, tài khoản đăng nhập (log) được tạo ghi lại những trang web được đề xuất mà chúng ta đã truy cập. Các tài khoản này chứa thông tin hữu ích như chính thuật ngữ truy vấn, địa chỉ IP của thiết bị được sử dụng, thời gian gửi truy vấn, thời gian chúng ta ở trên mỗi trang web và thứ tự chúng ta đã truy cập chúng —tất cả đều không nhận dạng chúng ta theo tên. Ngoài ra, tài khoản luồng nhấp chuột ghi lại đường dẫn được thực hiện khi chúng ta truy cập các trang web khác nhau cũng như điều hướng của chúng ta trong mỗi trang web. Khi chúng ta lướt Web, mỗi nhấp chuột chúng ta thực hiện, được ghi nhận ở đâu đó để sử dụng trong tương lai. Phần mềm có sẵn cho các doanh nghiệp cho phép họ thu thập dữ liệu luồng nhấp chuột được tạo bởi trang web của riêng họ — một công cụ tiếp thị có giá trị. Ví dụ: bằng cách cung cấp dữ liệu về việc sử dụng hệ thống, tài khoản đăng nhập có thể giúp phát hiện hoạt động độc hại như trộm cắp danh tính. Tài khoản đăng nhập cũng được sử dụng để đánh giá hiệu quả của quảng cáo trực tuyến, về cơ bản bằng cách đếm số lần khách truy cập trang web nhấp vào quảng cáo.
Bằng cách cho phép nhận dạng khách hàng, cookie được sử dụng để cá nhân hóa trải nghiệm lướt web của bạn. Khi bạn thực hiện lần truy cập đầu tiên vào một trang web đã chọn, một cookie, là một tệp văn bản nhỏ, thường bao gồm số nhận dạng trang web và số nhận dạng người dùng, sẽ được gửi đến máy tính của bạn, trừ khi bạn đã chặn việc sử dụng cookie. Mỗi lần bạn truy cập trang web này, cookie sẽ gửi một tin nhắn trở lại trang web và bằng cách này theo dõi các lượt truy cập của bạn. Như chúng ta sẽ thấy trong Chương 6, cookie thường được sử dụng để ghi lại dữ liệu luồng nhấp chuột, để theo dõi sở thích của bạn hoặc để thêm tên của bạn vào quảng cáo được nhắm mục tiêu.
Các trang mạng xã hội cũng tạo ra một lượng lớn dữ liệu, với Facebook và Twitter đứng đầu danh sách. Đến giữa năm 2016, Facebook có trung bình 1,71 tỷ người dùng hoạt động mỗi tháng, tất cả đều tạo ra dữ liệu, dẫn đến khoảng 1,5 petabyte (Pb; hoặc 1.000 Tb) dữ liệu đăng nhập web mỗi ngày. YouTube, trang web chia sẻ video phổ biến, đã có tác động rất lớn kể từ khi nó bắt đầu vào năm 2005 và một thông cáo báo chí gần đây của YouTube tuyên bố rằng có hơn một tỷ người dùng trên toàn thế giới. Dữ liệu có giá trị được tạo ra bởi các công cụ tìm kiếm và các trang mạng xã hội có thể được sử dụng trong nhiều lĩnh vực khác, ví dụ như khi xử lý các vấn đề sức khỏe.
Dữ liệu chăm sóc sức khỏe
Nếu chúng ta nhìn vào chăm sóc sức khỏe, chúng ta tìm thấy một khu vực liên quan đến một tỷ lệ lớn và ngày càng tăng của dân số thế giới và ngày càng được vi tính toán hóa (computerized). Hồ sơ sức khỏe điện tử đang dần trở thành tiêu chuẩn trong các bệnh viện và phòng khám của bác sĩ, với mục đích chính là giúp chia sẻ dữ liệu bệnh nhân với các bệnh viện và bác sĩ khác dễ dàng hơn, và từ đó tạo điều kiện cho việc cung cấp dịch vụ chăm sóc sức khỏe tốt hơn. Việc thu thập dữ liệu cá nhân thông qua các cảm biến có thể đeo được hoặc cấy ghép đang gia tăng, đặc biệt là để theo dõi sức khỏe, với nhiều người trong chúng ta sử dụng máy theo dõi thể dục cá nhân có độ phức tạp khác nhau tạo ra nhiều loại dữ liệu hơn bao giờ hết. Giờ đây, có thể theo dõi sức khỏe của bệnh nhân từ xa trong thời gian thực thông qua việc thu thập dữ liệu về huyết áp, mạch và nhiệt độ, do đó có khả năng giảm chi phí chăm sóc sức khỏe và cải thiện chất lượng cuộc sống. Các thiết bị giám sát từ xa này ngày càng trở nên tinh vi và hiện vượt xa các phép đo cơ bản để bao gồm theo dõi giấc ngủ và tốc độ bão hòa oxy động mạch.
Một số công ty đưa ra các ưu đãi để thuyết phục nhân viên sử dụng thiết bị tập thể dục đeo được và đáp ứng các mục tiêu nhất định như giảm cân hoặc một số bước nhất định được thực hiện mỗi ngày. Đổi lại việc được cung cấp thiết bị, nhân viên đồng ý chia sẻ dữ liệu với người sử dụng lao động. Điều này có vẻ hợp lý nhưng chắc chắn sẽ có những vấn đề riêng tư cần được xem xét, cùng với áp lực không mong muốn mà một số người có thể cảm thấy phải chịu khi chọn tham gia vào một chương trình như vậy.
Các hình thức giám sát nhân viên khác đang trở nên thường xuyên hơn, chẳng hạn như theo dõi tất cả các hoạt động của nhân viên trên máy tính và điện thoại thông minh do công ty cung cấp. Sử dụng phần mềm tùy chỉnh, theo dõi này có thể bao gồm mọi thứ từ giám sát trang web nào được truy cập để ghi lại các lần gõ phím riêng lẻ và từ giám sát trang web nào được truy cập để ghi nhật ký các lần nhấn phím riêng lẻ và kiểm tra xem máy tính có đang được sử dụng cho mục đích riêng tư như truy cập các trang web mạng xã hội hay không. Trong thời đại rò rỉ dữ liệu lớn, bảo mật là mối quan tâm ngày càng tăng và vì vậy dữ liệu của công ty phải được bảo vệ. Giám sát email và theo dõi các trang web truy cập chỉ là hai cách để giảm hành vi trộm cắp tài liệu nhạy cảm.
Như chúng ta đã thấy, dữ liệu sức khỏe cá nhân có thể được lấy từ các cảm biến, chẳng hạn như máy theo dõi thể dục hoặc thiết bị theo dõi sức khỏe. Tuy nhiên, phần lớn dữ liệu được thu thập từ các cảm biến là dành cho các mục đích y tế chuyên môn cao. Một số kho dữ liệu lớn nhất hiện có đang được tạo ra khi các nhà nghiên cứu nghiên cứu gen và giải trình tự bộ gen của nhiều loài khác nhau. Cấu trúc của phân tử axit deoxyribonucleic (DNA), nổi tiếng với việc giữ các hướng dẫn di truyền cho hoạt động của các sinh vật sống, lần đầu tiên được mô tả là chuỗi xoắn kép bởi James Watson và Francis Crick vào năm 1953. Một trong những dự án nghiên cứu được công bố rộng rãi nhất trong những năm gần đây là dự án bộ gen người quốc tế, xác định trình tự, hoặc thứ tự chính xác, của ba tỷ cặp cơ sở trong DNA của con người. Cuối cùng, dữ liệu này đang giúp các nhóm nghiên cứu trong việc nghiên cứu các bệnh di truyền.
Dữ liệu thời gian thực
Một số dữ liệu được thu thập, xử lý và sử dụng trong thời gian thực. Sự gia tăng sức mạnh xử lý vi tính toán đã cho phép tăng khả năng xử lý cũng như tạo ra dữ liệu đó một cách nhanh chóng. Đây là những hệ thống mà thời gian phản hồi là rất quan trọng và do đó dữ liệu phải được xử lý kịp thời. Ví dụ, Hệ thống định vị toàn cầu (GPS) sử dụng một hệ thống vệ tinh để quét Trái đất và gửi lại một lượng lớn dữ liệu thời gian thực. Thiết bị nhận GPS, có thể trong xe hơi hoặc điện thoại thông minh của bạn (‘thông minh’ chỉ ra rằng một mục, trong trường hợp này là điện thoại, có quyền truy cập Internet và khả năng cung cấp một số dịch vụ hoặc ứng dụng (ứng dụng) sau đó có thể được liên kết với nhau), xử lý các tín hiệu vệ tinh này và tính toán vị trí, thời gian và tốc độ của bạn.
Công nghệ này hiện đang được sử dụng trong việc phát triển các phương tiện không người lái hoặc tự lái. Chúng đã được sử dụng trong các lĩnh vực hạn chế, chuyên biệt như nhà máy và trang trại, và đang được phát triển bởi một số nhà sản xuất lớn, bao gồm Volvo, Tesla và Nissan. Các cảm biến và chương trình máy tính liên quan phải xử lý dữ liệu trong thời gian thực để điều hướng đáng tin cậy đến đích của bạn và kiểm soát chuyển động của xe liên quan đến những người tham gia giao thông khác. Điều này liên quan đến việc tạo trước các bản đồ 3D của các tuyến đường sẽ được sử dụng vì các cảm biến không thể đối phó với các tuyến đường không được lập bản đồ. Cảm biến radar được sử dụng để giám sát các giao thông khác, gửi lại dữ liệu đến một máy tính điều hành trung tâm bên ngoài để điều khiển xe. Các cảm biến phải được lập trình để phát hiện hình dạng và phân biệt giữa, ví dụ, một đứa trẻ chạy ra đường và một tờ báo thổi ngang nó; hoặc để phát hiện, ví dụ, bố trí giao thông khẩn cấp sau tai nạn. Tuy nhiên, những chiếc xe này vẫn chưa có khả năng phản ứng thích hợp với tất cả các vấn đề đặt ra bởi một môi trường luôn thay đổi.
Vụ tai nạn chết người đầu tiên liên quan đến một chiếc xe tự lái xảy ra vào năm 2016, khi cả người lái và hệ thống lái tự động đều không phản ứng với một chiếc xe cắt ngang đường đi của chiếc xe, có nghĩa là phanh không được áp dụng. Tesla, nhà sản xuất xe tự lái, trong một thông cáo báo chí tháng 6 năm 2016 đã đề cập đến “những trường hợp cực kỳ hiếm hoi của tác động”. Hệ thống lái tự động cảnh báo người lái xe luôn giữ tay trên vô lăng và thậm chí kiểm tra xem họ có đang làm như vậy không. Tesla tuyên bố rằng đây là trường hợp tử vong đầu tiên liên quan đến hệ thống lái tự động của họ trong 130 triệu dặm lái xe, so với một trường hợp tử vong trên 94 triệu dặm lái xe thường xuyên, không tự động ở Mỹ.
Người ta ước tính rằng mỗi chiếc xe tự lái sẽ tạo ra trung bình 30 Tb dữ liệu mỗi ngày, phần lớn trong số đó sẽ phải được xử lý gần như ngay lập tức. Một lĩnh vực nghiên cứu mới, được gọi là phân tích luồng, bỏ qua các phương pháp xử lý dữ liệu và thống kê truyền thống, hy vọng sẽ cung cấp phương tiện để đối phó với vấn đề dữ liệu lớn cụ thể này.
Dữ liệu thiên văn
Vào tháng 4 năm 2014, một báo cáo của Tập đoàn Dữ liệu Quốc tế ước tính rằng, vào năm 2020, vũ trụ kỹ thuật số sẽ là 44 nghìn tỷ gigabyte (Gb; hoặc 1.000 megabyte (Mb)), gấp khoảng 10 lần kích thước của nó vào năm 2013. Một khối lượng dữ liệu ngày càng tăng đang được tạo ra bởi kính viễn vọng. Ví dụ, Kính đại viễn vọng ở Chile là một kính viễn vọng quang học, thực sự bao gồm bốn kính viễn vọng, mỗi kính tạo ra lượng dữ liệu khổng lồ – 15 Tb một đêm, trung bình mỗi đêm. Nó sẽ dẫn đầu Khảo sát khái quát lớn, một dự án kéo dài mười năm liên tục tạo ra các bản đồ bầu trời đêm, tạo ra tổng cộng ước tính là 60 Pb (250 byte).
Thậm chí lớn hơn về mặt tạo dữ liệu là kính viễn vọng vô tuyến Square Kilometer Array Pathfinder (ASKAP) đang được xây dựng ở Úc và Nam Phi, dự kiến hoạt động vào năm 2018. Nó sẽ tạo ra 160 Tb dữ liệu thô mỗi giây ban đầu và hơn thế nữa khi các giai đoạn tiếp theo được hoàn thành. Không phải tất cả dữ liệu này sẽ được lưu trữ nhưng ngay cả như vậy, các siêu máy tính trên khắp thế giới sẽ cần thiết để phân tích dữ liệu còn lại.
Tất cả dữ liệu này có ích lợi gì?
Bây giờ, gần như không thể tham gia vào các hoạt động hàng ngày mà tránh việc một số dữ liệu cá nhân được thu thập bằng điện tử. Thanh toán siêu thị thu thập dữ liệu về những gì chúng ta mua; các hãng hàng không thu thập thông tin về việc sắp xếp chuyến đi của chúng ta khi chúng ta mua vé; và các ngân hàng thu thập dữ liệu tài chính của chúng ta.
Dữ liệu lớn được sử dụng rộng rãi trong thương mại và y học và có các ứng dụng trong luật, xã hội học, tiếp thị, y tế công cộng và tất cả các lĩnh vực khoa học tự nhiên. Dữ liệu dưới mọi hình thức của nó có khả năng cung cấp nhiều thông tin hữu ích nếu chúng ta có thể phát triển các cách để trích xuất nó. Các kỹ thuật mới kết hợp thống kê truyền thống và khoa học máy tính làm cho việc phân tích các bộ dữ liệu lớn ngày càng khả thi. Những kỹ thuật và thuật toán này được phát triển bởi các nhà thống kê và nhà khoa học máy tính, tìm kiếm các mẫu trong dữ liệu. Xác định mẫu quan trọng là chìa khóa cho sự thành công của phân tích dữ liệu lớn. Những thay đổi do thời đại kỹ thuật số mang lại đã thay đổi đáng kể cách thu thập, lưu trữ và phân tích dữ liệu. Cuộc cách mạng dữ liệu lớn đã cho chúng ta những chiếc xe thông minh và giám sát nhà.
Khả năng thu thập dữ liệu điện tử dẫn đến sự xuất hiện lĩnh vực khoa học dữ liệu thú vị, tập hợp các ngành thống kê và khoa học máy tính để phân tích số lượng lớn dữ liệu này để khám phá kiến thức mới trong các lĩnh vực ứng dụng liên ngành. Mục đích cuối cùng của việc làm việc với dữ liệu lớn là trích xuất thông tin hữu ích. Ví dụ, việc ra quyết định trong kinh doanh ngày càng dựa trên thông tin lượm lặt được từ dữ liệu lớn và kỳ vọng rất cao. Nhưng có những vấn đề quan trọng, nhất là với sự thiếu hụt các nhà khoa học dữ liệu được đào tạo có khả năng phát triển và quản lý hiệu quả các hệ thống cần thiết để trích xuất thông tin mong muốn.
Bằng cách sử dụng các phương pháp mới bắt nguồn từ thống kê, khoa học máy tính và trí tuệ nhân tạo, các thuật toán hiện đang được thiết kế dẫn đến những hiểu biết và tiến bộ mới trong khoa học. Ví dụ, mặc dù không thể dự đoán chính xác khi nào và ở đâu một trận động đất sẽ xảy ra, ngày càng có nhiều tổ chức đang sử dụng dữ liệu được thu thập bởi các cảm biến vệ tinh và mặt đất để theo dõi hoạt động địa chấn. Mục đích là để xác định khoảng nơi các trận động đất lớn có khả năng xảy ra trong dài hạn. Ví dụ, Cơ quan Khảo sát Địa chất Hoa Kỳ (USGS), một công ty lớn trong nghiên cứu địa chấn, ước tính vào năm 2016 rằng “có 76% xác suất một trận động đất mạnh 7 độ sẽ xảy ra trong vòng 30 năm tới ở miền bắc California”. Các xác suất như thế này giúp tập trung nguồn lực vào các biện pháp như đảm bảo rằng các tòa nhà có khả năng chịu được động đất tốt hơn và có các chương trình quản lý thiên tai. Một số công ty trong các lĩnh vực này và các lĩnh vực khác đang làm việc với dữ liệu lớn để cung cấp các phương pháp dự báo được cải thiện, điều không có sẵn trước khi dữ liệu lớn ra đời. Chúng ta cần xem xét những gì đặc biệt về dữ liệu lớn.
Đọc thêm
David J. Hand, Information Generation: How Data Rule Our World (Oneworld, 2007).
Jeffrey Quilter and Gary Urton (eds), Narrative Threads: Accounting and Recounting in Andean Khipu (University of Texas Press, 2002).
David Salsburg, The Lady Tasting Tea: How Statistics Revolutionized Science in the Twentieth Century (W.H. Freeman and Company, 2001).
Thucydides, History of the Peloponnesian War, ed. and intro. M. I. Finley, trans. Rex Warner (Penguin Classics, 1954).
Chương 2: Tại sao dữ liệu lớn lại đặc biệt?
Dữ liệu lớn không chỉ diễn ra mà còn liên quan chặt chẽ đến sự phát triển của công nghệ máy tính. Tốc độ tăng trưởng nhanh chóng về sức mạnh tính toán và lưu trữ đã dẫn đến việc thu thập nhiều dữ liệu hơn và, bất kể ai là người đầu tiên đặt ra thuật ngữ này, ‘dữ liệu lớn’ ban đầu chỉ là về kích thước. Tuy nhiên, không thể định nghĩa dữ liệu lớn duy chỉ về số lượng Pb, hoặc thậm chí Eb, đang được tạo và lưu trữ. Do vậy, một phương tiện hữu ích để nói về ‘dữ liệu lớn’ do bùng nổ dữ liệu được cung cấp bởi thuật ngữ ‘dữ liệu nhỏ’ – mặc dù nó không được sử dụng rộng rãi bởi các nhà thống kê. Các bộ dữ liệu lớn chắc chắn là lớn và phức tạp, nhưng để chúng ta đạt được định nghĩa, trước tiên chúng ta cần hiểu ‘dữ liệu nhỏ’ và vai trò của nó trong phân tích thống kê.
Dữ liệu lớn so với dữ liệu nhỏ
Năm 1919, Ronald Fisher, hiện được công nhận rộng rãi là người sáng lập thống kê hiện đại như một ngành học nghiêm ngặt về mặt học thuật, đã đến Trạm thí nghiệm nông nghiệp Rothamsted ở Anh để phân tích dữ liệu cây trồng. Dữ liệu đã được thu thập từ các thí nghiệm thực địa cổ điển được thực hiện tại Rothamsted từ những năm 1840, bao gồm cả công việc của họ về lúa mì mùa đông và lúa mạch mùa xuân và dữ liệu khí tượng từ trạm dã chiến. Fisher bắt đầu dự án Broadbalk kiểm tra tác động của các loại phân bón khác nhau đối với lúa mì, một dự án vẫn đang hoạt động cho đến ngày nay.
Nhận ra sự lộn xộn của dữ liệu, Fisher nổi tiếng gọi công việc ban đầu của mình ở đó là ‘cào qua đống bùn’. Tuy nhiên, bằng cách nghiên cứu tỉ mỉ các kết quả thí nghiệm đã được ghi lại cẩn thận trong sổ ghi chú bọc da, ông đã có thể hiểu được dữ liệu. Làm việc dưới những hạn chế của thời đại, trước khi có công nghệ máy tính ngày nay, Fisher chỉ được hỗ trợ bởi một máy tính cơ học vì dù sao ông cũng đã thực hiện thành công các phép tính trên bảy mươi năm dữ liệu tích lũy. Máy tính này, được gọi là Triệu phú/ Millionaire, dựa vào sức mạnh trên một quy trình quay tay tẻ nhạt, đã được đổi mới vào thời của nó, vì nó là máy tính thương mại đầu tiên có thể được sử dụng để thực hiện phép nhân. Công việc của Fisher rất chuyên sâu về tính toán và Triệu phú đóng một vai trò quan trọng trong việc cho phép ông thực hiện nhiều phép tính cần thiết mà bất kỳ máy tính hiện đại nào cũng sẽ hoàn thành trong vòng vài giây.
Mặc dù Fisher đã đối chiếu và phân tích rất nhiều dữ liệu, nhưng ngày nay nó sẽ không được coi là một khối lượng lớn và chắc chắn nó sẽ không được coi là ‘dữ liệu lớn’. Mấu chốt trong công việc của Fisher là sử dụng các thí nghiệm được xác định chính xác và kiểm soát cẩn thận, được thiết kế để tạo ra dữ liệu mẫu có cấu trúc cao, không thiên vị. Điều này rất cần thiết vì các phương pháp thống kê có sẵn chỉ có thể được áp dụng cho dữ liệu có cấu trúc. Thật vậy, những kỹ thuật vô giá này vẫn cung cấp nền tảng cho việc phân tích các bộ dữ liệu nhỏ, có cấu trúc. Tuy nhiên, những kỹ thuật đó không thể áp dụng cho lượng dữ liệu rất lớn mà chúng ta hiện có thể truy cập với rất nhiều nguồn kỹ thuật số khác nhau có sẵn cho chúng ta.
Dữ liệu lớn được xác định
Trong thời đại kỹ thuật số, chúng ta không còn hoàn toàn phụ thuộc vào các mẫu, vì chúng ta thường có thể thu thập tất cả dữ liệu chúng ta cần trên toàn bộ các tập hợp. Nhưng kích thước của các bộ dữ liệu ngày càng lớn này không thể một mình cung cấp định nghĩa cho thuật ngữ ‘dữ liệu lớn’ – chúng ta phải bao gồm sự phức tạp trong bất kỳ định nghĩa nào. Thay vì các mẫu ‘dữ liệu nhỏ’ được xây dựng cẩn thận, chúng ta hiện đang xử lý một lượng lớn dữ liệu, chưa được thu thập theo bất kỳ câu hỏi cụ thể nào trong đầu và thường không có cấu trúc. Để mô tả các tính năng chính làm cho dữ liệu lớn và hướng tới định nghĩa của thuật ngữ này, Doug Laney, viết vào năm 2001, đã đề xuất sử dụng ba chữ ‘v’: khối lượng/ volume, sự đa dạng/ variety và tốc độ/ velocity. Bằng cách lần lượt xem xét từng điều này, chúng ta có thể hiểu rõ hơn về thuật ngữ ‘dữ liệu lớn’ có nghĩa là gì.
Khối lượng
‘Khối lượng’ đề cập đến lượng dữ liệu điện tử hiện đang được thu thập và lưu trữ, đang tăng với tốc độ ngày càng tăng. Dữ liệu lớn là lớn, nhưng lớn như thế nào? Thật dễ dàng để đặt một kích thước cụ thể như biểu thị ‘lớn’ trong bối cảnh này, nhưng những gì được coi là ‘lớn’ mười năm trước không còn lớn theo tiêu chuẩn ngày nay. Việc thu thập dữ liệu đang phát triển với tốc độ nhanh đến mức bất kỳ giới hạn nào được chọn chắc chắn sẽ sớm trở nên lỗi thời. Vào năm 2012, IBM và Đại học Oxford đã báo cáo những phát hiện của Khảo sát công việc dữ liệu lớn của họ. Trong cuộc khảo sát quốc tế này với 1.144 chuyên gia làm việc ở chín mươi lăm quốc gia khác nhau, hơn một nửa đánh giá bộ dữ liệu từ 1 Tb đến 1 Pb là lớn, trong khi khoảng một phần ba số người được hỏi rơi vào danh mục ‘không biết’. Cuộc khảo sát yêu cầu người trả lời chọn một hoặc hai đặc điểm xác định của dữ liệu lớn từ tám mức lựa chọn; Chỉ có 10% bỏ phiếu cho “khối lượng dữ liệu lớn” với lựa chọn hàng đầu là “phạm vi thông tin lớn hơn”, thu hút 18%. Một lý do khác tại sao không thể có giới hạn dứt khoát chỉ dựa trên kích thước là vì các yếu tố khác, như lưu trữ và loại dữ liệu được thu thập, thay đổi theo thời gian và ảnh hưởng đến nhận thức của chúng ta về khối lượng. Tất nhiên, một số bộ dữ liệu thực sự rất lớn, bao gồm, ví dụ, những bộ dữ liệu thu được từ Máy va chạm Hadron Lớn tại CERN, máy gia tốc hạt hàng đầu thế giới, đã hoạt động từ năm 2008. Ngay cả sau khi chỉ trích xuất 1% tổng số dữ liệu được tạo ra, các nhà khoa học vẫn có 25 Pb để xử lý hàng năm. Nói chung, chúng ta có thể nói tiêu chí khối lượng được đáp ứng nếu tập dữ liệu sao cho chúng ta không thể thu thập, lưu trữ và phân tích nó bằng các phương pháp thống kê và tính toán truyền thống. Dữ liệu cảm biến, chẳng hạn như dữ liệu được tạo ra bởi Máy va chạm Hadron Lớn, chỉ là một loại dữ liệu lớn, vì vậy hãy xem xét một số dữ liệu khác.
Sự đa dạng
Mặc dù bạn có thể thường thấy các thuật ngữ ‘Internet’ và ‘World Wide Web’ được sử dụng thay thế cho nhau, nhưng chúng thực sự rất khác nhau. Internet là một mạng lưới, bao gồm máy tính, mạng máy tính, mạng cục bộ (LAN), vệ tinh, điện thoại di động và các thiết bị điện tử khác, tất cả được liên kết với nhau và có thể gửi các gói dữ liệu cho nhau, chúng thực hiện bằng địa chỉ IP (giao thức Internet). World Wide Web (www, hoặc Web), được mô tả bởi nhà phát minh của nó, TJ Berners-Lee, là “một hệ thống thông tin toàn cầu”, khai thác truy cập Internet để tất cả những người có máy tính và kết nối có thể giao tiếp với những người dùng khác thông qua các phương tiện như email, nhắn tin tức thời, mạng xã hội và tin nhắn. Người đăng ký ISP (nhà cung cấp dịch vụ Internet) có thể kết nối với Internet và do đó truy cập Web và nhiều dịch vụ khác.
Khi chúng ta được kết nối với Web, chúng ta có quyền truy cập vào một bộ sưu tập dữ liệu hỗn loạn, từ các nguồn, cả đáng tin cậy và đáng ngờ, dễ bị lặp lại và lỗi. Đây là một chặng đường dài từ dữ liệu sạch sẽ và chính xác theo yêu cầu của thống kê truyền thống. Mặc dù dữ liệu được thu thập từ Web có thể có cấu trúc, không có cấu trúc hoặc bán cấu trúc dẫn đến sự đa dạng đáng kể (ví dụ: các tài liệu hoặc bài đăng được xử lý văn bản không có cấu trúc được tìm thấy trên các trang web mạng xã hội; và bảng tính bán cấu trúc), hầu hết dữ liệu lớn có nguồn gốc từ Web là không có cấu trúc. Ví dụ, người dùng Twitter xuất bản khoảng 500 triệu tin nhắn 140 ký tự hoặc thông điệp ngắn/ tweet mỗi ngày trên toàn thế giới. Những thông điệp ngắn này có giá trị thương mại và thường được phân tích theo tình cảm được thể hiện là tích cực, tiêu cực hay trung lập. Lĩnh vực phân tích cảm xúc mới này đòi hỏi các kỹ thuật được phát triển đặc biệt và là điều chúng ta có thể làm hiệu quả chỉ bằng cách sử dụng phân tích dữ liệu lớn. Mặc dù rất nhiều dữ liệu được thu thập bởi các bệnh viện, quân đội và nhiều doanh nghiệp thương mại cho một số mục đích, nhưng cuối cùng tất cả đều có thể được phân loại là có cấu trúc, không có cấu trúc hoặc bán cấu trúc.
Tốc độ
Dữ liệu hiện đang phát trực tuyến liên tục từ các nguồn như Web, điện thoại thông minh và cảm biến. Vận tốc nhất thiết phải được kết nối với khối lượng: dữ liệu được tạo ra càng nhanh thì càng có nhiều. Ví dụ: các thông điệp trên phương tiện truyền thông xã hội hiện đang ‘lan truyền’ được truyền đi theo cách có hiệu ứng quả cầu tuyết: Tôi đăng một cái gì đó trên phương tiện truyền thông xã hội, bạn bè của tôi nhìn vào nó và mỗi người chia sẻ nó với bạn bè của họ, v.v. Rất nhanh chóng những thông điệp này đi khắp thế giới.
Vận tốc cũng đề cập đến tốc độ dữ liệu được xử lý điện tử. Ví dụ, dữ liệu cảm biến, chẳng hạn như được tạo ra bởi một chiếc xe tự lái, nhất thiết phải được tạo ra trong thời gian thực. Nếu xe hoạt động đáng tin cậy, dữ liệu, được gửi không dây đến trung tâm, phải được phân tích rất nhanh để có thể gửi lại các hướng dẫn cần thiết kịp thời cho xe.
Sự đa dạng có thể được coi là một khía cạnh bổ sung của khái niệm vận tốc, đề cập đến tốc độ thay đổi trong luồng dữ liệu, chẳng hạn như sự gia tăng đáng kể luồng dữ liệu trong thời gian cao điểm. Điều này rất quan trọng vì hệ thống máy tính dễ bị hỏng vào những thời điểm này.
Tính xác thực/ Veracity
Cũng như ba ‘v’ ban đầu do Laney đề xuất, chúng ta có thể thêm ‘tính xác thực’ làm phần thứ tư. Tính xác thực đề cập đến chất lượng của dữ liệu được thu thập. Dữ liệu chính xác và đáng tin cậy là dấu hiệu của phân tích thống kê trong thế kỷ qua. Fisher và những người khác đã cố gắng đưa ra các phương pháp gói gọn hai khái niệm này, nhưng dữ liệu được tạo ra trong thời đại kỹ thuật số thường không có cấu trúc và thường được thu thập mà không có thiết kế thử nghiệm hoặc, thực sự, bất kỳ khái niệm nào về những câu hỏi có thể được quan tâm. Tuy nhiên, chúng ta đã tìm cách thu thập thông tin từ đống lộn xộn này. Lấy ví dụ, dữ liệu được tạo ra bởi các mạng xã hội. Dữ liệu này về bản chất là không chính xác, không chắc chắn và thường thông tin được đăng đơn giản là không đúng sự thật. Vậy làm thế nào chúng ta có thể tin tưởng dữ liệu để mang lại kết quả có ý nghĩa? Khối lượng có thể giúp khắc phục những vấn đề này – như chúng ta đã thấy trong Chương 1, khi Thucydides mô tả các lực lượng Plataean giao chiến với số lượng binh sĩ lớn nhất có thể đếm gạch để có nhiều khả năng đạt được (gần) chiều cao chính xác của bức tường mà họ muốn trèo qua. Tuy nhiên, chúng ta cần thận trọng hơn, như chúng ta biết từ lý thuyết thống kê, khối lượng lớn hơn có thể dẫn đến kết quả ngược lại, trong đó, với đủ dữ liệu, chúng ta có thể tìm thấy nhiều tương quan giả mạo.
Tính có thể quan sát/ visualization và các chữ ‘v khác’
‘V’ đã trở thành chữ cái được lựa chọn, với các định nghĩa cạnh tranh bổ sung hoặc thay thế các thuật ngữ như ‘tính dễ bị tổn thương’/ vulnerability và ‘khả năng tồn tại’/ viability vào ba thuật ngữ ban đầu của Laney — điều quan trọng nhất có lẽ trong số những bổ sung này là ‘giá trị’/ value và ‘có thể quan sát’. Giá trị thường đề cập đến chất lượng của các kết quả thu được từ phân tích dữ liệu lớn. Nó cũng đã được sử dụng để mô tả việc bán dữ liệu của các doanh nghiệp thương mại cho các công ty sau đó xử lý nó bằng cách sử dụng phân tích của riêng họ, và vì vậy nó là một thuật ngữ thường được nhắc đến trong giới kinh doanh dữ liệu.
Có thể quan sát không phải là một tính năng đặc trưng của dữ liệu lớn, nhưng nó rất quan trọng trong việc trình bày và truyền đạt kết quả phân tích. Các biểu đồ hình tròn tĩnh và biểu đồ thanh quen thuộc giúp chúng ta hiểu các bộ dữ liệu nhỏ đã được phát triển hơn nữa để hỗ trợ giải thích trực quan dữ liệu lớn, nhưng chúng bị hạn chế về khả năng ứng dụng. Đồ hoạ thông tin/ infographics, ví dụ, cung cấp một bản trình bày phức tạp hơn, nhưng là tĩnh. Vì dữ liệu lớn liên tục được thêm vào, các hình ảnh trực quan tốt nhất có tính tương tác cho người dùng và được cập nhật thường xuyên bởi người khởi tạo. Ví dụ: khi chúng ta sử dụng GPS để lập kế hoạch hành trình bằng ô tô, chúng ta đang truy cập đồ họa có tính tương tác cao, dựa trên dữ liệu vệ tinh, để theo dõi vị trí của chúng ta.
Kết hợp với nhau, bốn đặc điểm chính của dữ liệu lớn — khối lượng, sự đa dạng, tốc độ và tính xác thực — đưa ra một thách thức đáng kể trong quản lý dữ liệu. Những lợi thế mà chúng ta mong đợi đạt được từ việc đáp ứng thách thức này và các câu hỏi chúng ta hy vọng sẽ trả lời với dữ liệu lớn, có thể được hiểu thông qua khai thác dữ liệu.
Khai thác dữ liệu lớn/ Big data mining
“Dữ liệu là loại dầu mỏ mới”, một cụm từ phổ biến giữa các nhà lãnh đạo trong ngành công nghiệp, thương mại và chính trị, thường được gán cho Clive Humby vào năm 2006, người khởi xướng thẻ khách hàng thân thiết của Tesco. Đó là một cụm từ hấp dẫn và gợi ý rằng dữ liệu, giống như dầu, cực kỳ có giá trị, nhưng trước tiên phải được xử lý, trước khi giá trị đó có thể được nhận ra. Cụm từ này chủ yếu được sử dụng như một mưu đồ tiếp thị của các nhà cung cấp phân tích dữ liệu, hy vọng bán sản phẩm của họ bằng cách thuyết phục các công ty rằng dữ liệu lớn là tương lai. Nó cũng có thể như vậy, nhưng phép ẩn dụ chỉ giữ cho đến nay. Một khi bạn có dầu mỏ, bạn có một mặt hàng có thể bán được. Không như vậy với dữ liệu lớn; Trừ khi bạn có dữ liệu phù hợp, bạn không thể tạo ra gì có giá trị. Quyền sở hữu là một vấn đề; Quyền riêng tư là một vấn đề; Và, không giống như dầu mỏ, dữ liệu dường như không phải là một nguồn tài nguyên hữu hạn. Tuy nhiên, tiếp tục lỏng lẻo với phép ẩn dụ công nghiệp, khai thác dữ liệu lớn là nhiệm vụ trích xuất thông tin hữu ích và có giá trị từ các bộ dữ liệu khổng lồ.
Sử dụng các phương pháp và thuật toán trong khai thác dữ liệu và học cho máy/ machine learning, không chỉ có thể phát hiện các mẫu không thông thường hoặc bất thường trong dữ liệu mà còn có thể dự đoán chúng. Để có được loại kiến thức này từ các bộ dữ liệu lớn, các kỹ thuật học cho máy có giám sát hoặc không giám sát có thể được sử dụng. Học cho máy có giám sát có thể được coi là gần so sánh với việc học từ ví dụ ở người. Sử dụng dữ liệu để đào tạo, trong đó các ví dụ chính xác được dán nhãn, một chương trình máy tính phát triển một quy tắc hoặc thuật toán để phân loại các ví dụ mới. Thuật toán này được kiểm tra bằng cách sử dụng dữ liệu thử nghiệm. Ngược lại, các thuật toán học tập không giám sát sử dụng dữ liệu đầu vào không được gắn nhãn và không có mục tiêu nào được đưa ra; Chúng được thiết kế để khám phá dữ liệu và khám phá các mẫu ẩn.
Ví dụ: hãy xem xét phát hiện gian lận thẻ tín dụng và xem cách mỗi phương pháp được sử dụng.
Phát hiện gian lận thẻ tín dụng
Rất nhiều nỗ lực đi vào việc phát hiện và ngăn chặn gian lận thẻ tín dụng. Nếu bạn không may nhận được một cuộc gọi điện thoại từ văn phòng phát hiện gian lận thẻ tín dụng của mình, bạn có thể tự hỏi làm thế nào để đạt được quyết định rằng giao dịch mua gần đây được thực hiện trên thẻ của bạn có khả năng bị gian lận. Với số lượng giao dịch thẻ tín dụng khổng lồ, việc con người kiểm tra giao dịch bằng các kỹ thuật phân tích dữ liệu truyền thống không còn khả thi và do đó phân tích dữ liệu lớn ngày càng trở nên cần thiết. Có thể hiểu, các tổ chức tài chính không sẵn sàng chia sẻ chi tiết về các phương pháp phát hiện gian lận của họ vì làm như vậy sẽ cung cấp cho tội phạm mạng thông tin họ cần để phát triển các cách xung quanh nó. Tuy nhiên, các nét vẽ phác thể hiện một bức tranh thú vị.
Có một số tình huống có thể xảy ra nhưng chúng ta có thể xem xét ngân hàng cá nhân và xem xét trường hợp thẻ tín dụng đã bị đánh cắp và sử dụng cùng với thông tin bị đánh cắp khác, chẳng hạn như mã PIN thẻ (số nhận dạng cá nhân). Trong trường hợp này, thẻ có thể cho thấy sự gia tăng đột ngột về chi tiêu — một gian lận dễ dàng được phát hiện bởi cơ quan phát hành thẻ. Thường xuyên hơn, một kẻ lừa đảo trước tiên sẽ sử dụng thẻ bị đánh cắp cho một ‘giao dịch thử nghiệm’ trong đó một cái gì đó rẻ tiền được mua. Nếu điều này không gây ra bất kỳ báo động nào, thì một số tiền lớn hơn sẽ được thực hiện. Các giao dịch như vậy có thể hoặc không thể là gian lận – có thể chủ thẻ đã mua thứ gì đó ngoài mô hình mua hàng thông thường của họ hoặc có thể họ thực sự chỉ chi tiêu rất nhiều trong tháng đó. Vậy làm thế nào để chúng ta phát hiện giao dịch nào là gian lận? Trước tiên, chúng ta hãy xem xét một kỹ thuật không được giám sát, được gọi là phân cụm/ clustering và cách nó có thể được sử dụng trong tình huống này.
Phân cụm
Dựa trên các thuật toán trí tuệ nhân tạo, các phương pháp phân cụm có thể được sử dụng để phát hiện sự bất thường trong hành vi mua hàng của khách hàng. Chúng ta đang tìm kiếm các mẫu trong dữ liệu giao dịch và muốn phát hiện bất kỳ điều gì bất thường hoặc đáng ngờ có thể hoặc không thể là gian lận.
Một công ty thẻ tín dụng thu thập rất nhiều dữ liệu và sử dụng nó để tạo thành hồ sơ cho thấy hành vi mua hàng của khách hàng của họ. Các cụm cấu hình có thuộc tính tương tự sau đó được xác định kiểu điện tử bằng cách sử dụng chương trình máy tính lặp đi lặp lại (tức là lặp lại một quá trình để tạo ra kết quả). Ví dụ: cụm có thể được xác định trên các tài khoản có phạm vi chi tiêu hoặc vị trí điển hình, giới hạn chi tiêu trên của khách hàng hoặc trên loại mặt hàng đã mua, mỗi phân cụm dẫn đến một cụm riêng biệt. Khi dữ liệu được thu thập bởi nhà cung cấp thẻ tín dụng, nó không mang bất kỳ nhãn nào cho biết các giao dịch là chính hãng hay gian lận. Nhiệm vụ của chúng ta là sử dụng dữ liệu này làm đầu vào và, sử dụng một thuật toán phù hợp, phân loại chính xác các giao dịch. Để làm điều này, chúng ta sẽ cần tìm các nhóm hoặc cụm tương tự trong dữ liệu đầu vào. Vì vậy, ví dụ: chúng tôi có thể nhóm dữ liệu theo số tiền chi tiêu, vị trí diễn ra giao dịch, loại giao dịch được thực hiện hoặc tuổi của chủ thẻ. Khi một giao dịch mới được thực hiện, nhận dạng cụm được tính cho giao dịch đó và nếu nó khác với nhận dạng cụm hiện có cho khách hàng đó, nó được coi là đáng ngờ. Ngay cả khi nó nằm trong cụm thông thường, nếu nó đủ xa trung tâm của cụm, nó vẫn có thể khơi dậy sự nghi ngờ.
Ví dụ, giả sử một bà cụ 83 tuổi sống ở Pasadena mua một chiếc xe thể thao hào nhoáng; Nếu điều này không phù hợp với hành vi mua sắm thông thường của bà ấy, ví dụ, cửa hàng tạp hóa và ghé thăm tiệm làm tóc, nó sẽ được coi là bất thường. Bất cứ điều gì khác thường, như giao dịch mua này, được coi là đáng để điều tra thêm, thường bắt đầu bằng cách liên hệ với chủ sở hữu thẻ. Trong Hình 1, chúng ta thấy một ví dụ rất đơn giản về sơ đồ cụm đại diện cho tình huống này.
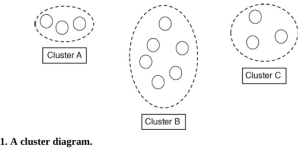
Cụm B cho thấy chi tiêu hàng tháng thông thường của bà tập trung với những người khác có chi tiêu hàng tháng tương tự. Bây giờ, trong một số trường hợp, ví dụ như khi kì nghỉ hàng năm, hoàn cảnh của bà, chi tiêu của bà trong tháng tăng lên, có lẽ nên nhóm bà với những người ở cụm C, không quá xa cụm B và vì vậy không quá khác biệt. Mặc dù vậy, vì nó nằm trong một cụm khác, nó sẽ được kiểm tra là hoạt động tài khoản đáng ngờ, nhưng việc mua chiếc xe thể thao hào nhoáng trên tài khoản của bà, sẽ đặt chi tiêu này vào Cụm A, rất xa so với cụm thông thường của bà ấy và do đó rất khó phản ánh rằng việc mua hàng là hợp pháp.
Trái ngược với tình huống này, nếu chúng ta đã có một bộ ví dụ mà chúng ta biết gian lận đã xảy ra, thay vì các thuật toán phân cụm, chúng ta có thể sử dụng các phương pháp phân loại/ classification, cung cấp một kỹ thuật khai thác dữ liệu khác được sử dụng để phát hiện gian lận.
Phân loại
Phân loại, một kỹ thuật học tập có giám sát, đòi hỏi kiến thức có trước về các nhóm liên quan. Chúng ta bắt đầu với một tập dữ liệu trong đó mỗi quan sát đã được dán nhãn hoặc phân loại chính xác. Điều này được chia thành một bộ cho đào tạo, cho phép chúng ta xây dựng một mô hình phân loại dữ liệu và một bộ thử nghiệm, được sử dụng để kiểm tra xem mô hình có phải là một mô hình tốt hay không. Sau đó, chúng ta có thể sử dụng mô hình này để phân loại các quan sát mới khi chúng phát sinh.
Để minh họa phân loại, chúng tôi sẽ xây dựng một mô hình cây quyết định nhỏ để phát hiện gian lận thẻ tín dụng.
Để xây dựng cây quyết định của chúng ta, chúng ta hãy giả sử rằng dữ liệu giao dịch thẻ tín dụng đã được thu thập và các giao dịch được phân loại là chính hãng hoặc gian lận dựa trên kiến thức đã có của chúng ta, được cung cấp, như thể hiện trong Hình 2.
| Thẻ có bị báo là bị đánh cắp hoặc bị mất không? | Món đồ được mua có gì bất thường không? | Khách hàng có được gọi điện và hỏi xem họ có mua hàng hay không? | Phân loại |
| Không | Không | Giao dịch chính chủ | |
| Không | Có | Có | Giao dịch chính chủ |
| Không | Có | Không | Giao dịch gian lận |
| Có | Giao dịch gian lận |
- Fraud dataset with known classifications. Tập dữ liệu gian lận có phân loại đã biết.
Sử dụng dữ liệu này, chúng ta có thể xây dựng cây quyết định được hiển thị trong Hình 3, điều này sẽ cho phép máy tính phân loại các giao dịch mới vào hệ thống. Chúng ta muốn đi đến một trong hai phân loại giao dịch có thể, chính chủ hoặc gian lận, bằng cách đặt một loạt câu hỏi.
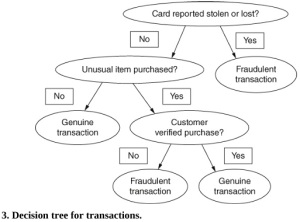
Bằng cách bắt đầu từ đỉnh của cây trong Hình 3, chúng ta có một loạt các câu hỏi kiểm tra sẽ cho phép chúng ta phân loại một giao dịch mới.
Ví dụ: nếu tài khoản của ông Smith cho thấy ông đã báo cáo thẻ tín dụng của mình bị mất hoặc bị đánh cắp, thì bất kỳ nỗ lực nào để sử dụng nó đều bị coi là gian lận. Nếu thẻ chưa được báo cáo bị mất hoặc bị đánh cắp, thì hệ thống sẽ kiểm tra xem một mặt hàng bất thường hoặc một mặt hàng có giá bất thường cho khách hàng này đã được mua hay chưa. Nếu không, thì giao dịch được coi là không có gì khác thường và được dán nhãn là chính chủ. Mặt khác, nếu vật phẩm bất thường thì một cuộc gọi điện thoại cho ông Smith sẽ được kích hoạt. Nếu ông ấy xác nhận rằng ông đã mua hàng, thì nó được coi là chính chủ; Nếu không, là gian lận.
Sau khi đi đến một định nghĩa không chính thống về dữ liệu lớn và xem xét các loại câu hỏi có thể được trả lời bằng cách khai thác dữ liệu lớn, bây giờ chúng ta hãy chuyển sang các vấn đề lưu trữ dữ liệu.
Đọc thêm
Joan Fisher Box, R. A. Fisher: The Life of a Scientist (Wiley, 1978).
David J. Hand, Statistics: A Very Short Introduction (Oxford University Press, 2008).
Viktor Mayer-Schönberger and Kenneth Cukier, Big Data: A Revolution That Will Transform How We Live, Work, and Think (Mariner Books, 2014).
Chương 3: Lưu trữ dữ liệu lớn
Ổ cứng đầu tiên, được phát triển và bán bởi IBM tại San Jose, California, có dung lượng lưu trữ khoảng 5 Mb, được giữ trên năm mươi đĩa, mỗi đĩa có đường kính 24 inch (60,96 cm). Đây là công nghệ tiên tiến vào năm 1956. Thiết bị này có kích thước vật lý khổng lồ, nặng hơn 1 tấn và là một phần của máy tính lớn. Vào thời điểm Apollo 11 hạ cánh xuống mặt trăng vào năm 1969, Trung tâm Tàu vũ trụ có người lái của NASA ở Houston đã sử dụng các máy tính lớn có bộ nhớ lên tới 8 Mb. Thật ngạc nhiên, máy tính cho tàu đổ bộ mặt trăng Apollo 11, do Neil Armstrong chỉ huy, chỉ có bộ nhớ 64 kilobyte (Kb).
Công nghệ máy vi tính phát triển nhanh chóng và khi bắt đầu bùng nổ máy tính cá nhân vào những năm 1980, ổ cứng trung bình trên PC là 5 Mb, tuy điều này không phải lúc nào cũng đúng. Như vậy đủ lưu trữ một hoặc hai bức ảnh hoặc hình ảnh ngày nay. Dung lượng lưu trữ máy tính tăng rất nhanh và mặc dù lưu trữ máy tính cá nhân không theo kịp lưu trữ dữ liệu lớn, nhưng nó đã tăng lên đáng kể trong những năm gần đây. Bây giờ, bạn có thể mua một PC có ổ cứng 8 Tb hoặc thậm chí lớn hơn. Ổ đĩa flash hiện có sẵn với 1 Tb dung lượng lưu trữ, đủ để lưu trữ khoảng 500 giờ phim hoặc hơn 300.000 ảnh. Nghe có vẻ rất nhiều cho đến khi chúng ta đối chiếu nó với ước tính 2,5 Eb dữ liệu mới được tạo ra mỗi ngày.
Khi sự thay đổi từ cổng van sang bóng bán dẫn diễn ra vào những năm 1960, số lượng bóng bán dẫn có thể được đặt trên một con chip tăng lên rất nhanh, gần như phù hợp với Định luật Moore, mà chúng ta sẽ thảo luận trong phần tiếp theo. Và mặc dù dự đoán rằng giới hạn thu nhỏ sắp tới hạn, nó vẫn tiếp tục ở mức xấp xỉ hợp lý và hữu ích. Giờ đây, chúng ta có thể nhồi nhét hàng tỷ bóng bán dẫn, ngày càng nhanh hơn vào một con chip, cho phép chúng ta lưu trữ số lượng dữ liệu lớn hơn bao giờ hết, trong khi bộ xử lý đa lõi cùng với phần mềm đa luồng giúp xử lý dữ liệu đó.
Định luật Moore
Năm 1965, Gordon Moore, người trở thành người đồng sáng lập Intel, đã đưa ra dự đoán nổi tiếng rằng trong mười năm tới, số lượng bóng bán dẫn được tích hợp trong một con chip sẽ tăng gấp đôi sau mỗi hai mươi bốn tháng. Năm 1975, ông đã thay đổi dự đoán của mình và đề xuất độ phức tạp sẽ tăng gấp đôi sau mỗi mười hai tháng trong năm năm và sau đó giảm trở lại gấp đôi sau mỗi hai mươi bốn tháng. David House, một đồng nghiệp tại Intel, sau khi tính đến tốc độ ngày càng tăng của bóng bán dẫn, cho rằng hiệu suất của vi mạch sẽ tăng gấp đôi sau mỗi mười tám tháng, và hiện tại đó là dự đoán thứ hai thường được sử dụng cho Định luật Moore. Dự đoán này đã được chứng minh là chính xác đáng kể; Máy tính thực sự đã trở nên nhanh hơn, rẻ hơn và mạnh hơn kể từ năm 1965, nhưng bản thân Moore cảm thấy rằng “định luật” này sẽ sớm bị mất đi.
Theo M. Mitchell Waldrop, trong một bài báo đăng trên ấn bản tháng 2 năm 2016 của tạp chí khoa học Nature, sự kết thúc thực sự đã gần kề đối với Định luật Moore. Bộ vi xử lý là mạch tích hợp chịu trách nhiệm thực hiện các hướng dẫn được cung cấp bởi chương trình máy tính. Điều này thường bao gồm hàng tỷ bóng bán dẫn, được nhúng trong một không gian nhỏ trên vi mạch silicon. Một cổng trong mỗi bóng bán dẫn cho phép nó được bật hoặc tắt và do đó nó có thể được sử dụng để lưu trữ 0 và 1. Một dòng điện đầu vào rất nhỏ chạy qua mỗi cổng bóng bán dẫn và tạo ra dòng điện đầu ra khuếch đại khi cổng đóng. Mitchell Waldrop quan tâm đến khoảng cách giữa các cổng, hiện đang ở khoảng cách 14 nanomet trong các bộ vi xử lý hàng đầu [2024: 3 nanomet], và tuyên bố rằng các vấn đề sinh nhiệt gây ra bởi mạch gần hơn và cách nó được tản nhiệt hiệu quả đang khiến sự tăng trưởng theo cấp số nhân được dự đoán bởi Định luật Moore chùn bước, điều này đã thu hút sự chú ý của chúng tôi đến các giới hạn cơ bản mà ông thấy đang nhanh chóng đến gần.
Một nanomet là 10−9 mét, hoặc một phần triệu milimét. Để đặt điều này trong bối cảnh, một sợi tóc của con người có đường kính khoảng 75.000 nanomet và đường kính của một nguyên tử là từ 0,1 đến 0,5 nanomet. Paolo Gargini, người làm việc cho Intel, tuyên bố rằng giới hạn khoảng cách sẽ là 2 hoặc 3 nanomet và sẽ đạt được trong tương lai không xa, có thể sớm nhất là vào những năm 2020. Waldrop suy đoán rằng “ở quy mô đó, hành vi của electron sẽ bị chi phối bởi sự không chắc chắn lượng tử sẽ khiến các bóng bán dẫn trở nên vô vọng không đáng tin cậy”. Như chúng ta sẽ thấy trong Chương 7, có vẻ như rất có khả năng máy tính lượng tử, một công nghệ vẫn còn sơ khai, cuối cùng, sẽ đưa tới con đường phía trước.
Định luật Moore hiện cũng có thể áp dụng cho tốc độ tăng trưởng dữ liệu vì số lượng được tạo ra dường như tăng gấp đôi sau mỗi hai năm. Dữ liệu tăng khi dung lượng lưu trữ tăng và khả năng xử lý dữ liệu tăng lên. Tất cả chúng ta đều được hưởng lợi: Netflix, điện thoại thông minh, Internet of Things (IoT; một cách thuận tiện để đề cập đến số lượng lớn các cảm biến điện tử được kết nối với Internet) và điện toán đám mây (một mạng lưới các máy chủ được kết nối với nhau trên toàn thế giới), trong số những ứng dụng khác nhau, tất cả đều trở nên khả thi vì sự tăng trưởng theo cấp số nhân được dự đoán bởi Định luật Moore. Tất cả dữ liệu được tạo ra này phải được lưu trữ và chúng ta xem xét tiếp điều này sau đây.
Lưu trữ dữ liệu có cấu trúc
Bất kỳ ai sử dụng máy tính cá nhân, máy tính xách tay hoặc điện thoại thông minh đều truy cập dữ liệu được lưu trữ trong cơ sở dữ liệu. Dữ liệu có cấu trúc, chẳng hạn như bảng sao kê ngân hàng và sổ địa chỉ điện tử, được lưu trữ trong cơ sở dữ liệu quan hệ. Để quản lý tất cả dữ liệu có cấu trúc này, hệ thống quản lý cơ sở dữ liệu quan hệ (relational database management system RDBMS) được sử dụng để tạo, duy trì, truy cập và thao tác dữ liệu. Bước đầu tiên là thiết kế lược đồ cơ sở dữ liệu (tức là cấu trúc của cơ sở dữ liệu). Để đạt được điều này, chúng ta cần biết các trường dữ liệu và có thể sắp xếp chúng trong các bảng, sau đó chúng ta cần xác định mối quan hệ giữa các bảng. Khi điều này đã được thực hiện và cơ sở dữ liệu được xây dựng, chúng ta có thể điền dữ liệu và thẩm vấn nó bằng ngôn ngữ truy vấn có cấu trúc (structured query language SQL).
Rõ ràng các bảng phải được thiết kế cẩn thận và nó sẽ đòi hỏi rất nhiều công việc để tạo ra những thay đổi đáng kể. Tuy nhiên, không nên đánh giá thấp mô hình quan hệ. Đối với nhiều ứng dụng dữ liệu có cấu trúc, nó nhanh chóng và đáng tin cậy. Một khía cạnh quan trọng của thiết kế cơ sở dữ liệu quan hệ liên quan đến một quá trình gọi là chuẩn hóa bao gồm giảm trùng lặp dữ liệu đến mức tối thiểu và do đó giảm yêu cầu lưu trữ. Điều này cho phép truy vấn nhanh hơn, nhưng ngay cả khi khối lượng dữ liệu tăng lên, hiệu ứng/ performance của các cơ sở dữ liệu truyền thống này sẽ giảm.
Vấn đề nằm ở một trong những khả năng nâng cấp. Vì cơ sở dữ liệu quan hệ về cơ bản được thiết kế để chạy trên chỉ một máy chủ, khi ngày càng có nhiều dữ liệu được thêm vào, chúng trở nên chậm và không đáng tin cậy. Cách duy nhất để đạt được khả năng nâng cấp là thêm nhiều sức mạnh tính toán hơn, lại có giới hạn của nó. Đây được gọi là khả năng mở rộng theo chiều dọc. Vì vậy, mặc dù dữ liệu có cấu trúc thường được lưu trữ và quản lý trong RDBMS, nhưng khi dữ liệu lớn, tính bằng terabyte hoặc petabyte và hơn thế nữa, RDBMS không còn hoạt động hiệu quả, ngay cả đối với dữ liệu có cấu trúc.
Một tính năng quan trọng của cơ sở dữ liệu quan hệ và lý do chính đáng để tiếp tục sử dụng chúng là chúng phù hợp với nhóm thuộc tính sau: tính nguyên tử (atomicity), tính nhất quán (consistency), cách biệt (isolation) và bền vững (durability), thường được gọi là ACID. Tính nguyên tử đảm bảo rằng các giao dịch không đầy đủ không thể cập nhật cơ sở dữ liệu; tính nhất quán loại trừ dữ liệu không hợp lệ; cách biệt đảm bảo một giao dịch không can thiệp vào một giao dịch khác; và bền vững có nghĩa là cơ sở dữ liệu phải cập nhật trước khi giao dịch tiếp theo được thực hiện. Tất cả những điều trên là những thuộc tính mong muốn, nhưng lưu trữ và truy cập dữ liệu lớn, hầu hết không có cấu trúc, đòi hỏi một cách tiếp cận khác.
Lưu trữ dữ liệu phi cấu trúc
Đối với dữ liệu phi cấu trúc, RDBMS không phù hợp vì nhiều lý do, nhất là một khi lược đồ cơ sở dữ liệu quan hệ đã được xây dựng, rất khó để thay đổi nó. Ngoài ra, dữ liệu phi cấu trúc không thể được tổ chức thuận tiện thành các hàng và cột. Như chúng ta đã thấy, dữ liệu lớn thường có tốc độ cao và được tạo ra trong thời gian thực với các yêu cầu xử lý thời gian thực, vì vậy mặc dù RDBMS là tuyệt vời cho nhiều mục đích và phục vụ chúng ta tốt, với sự bùng nổ dữ liệu hiện tại, đã có nghiên cứu chuyên sâu về các kỹ thuật lưu trữ và quản lý mới.
Để lưu trữ các bộ dữ liệu khổng lồ này, dữ liệu được phân phối trên các máy chủ. Khi số lượng máy chủ liên quan tăng lên, khả năng thất bại tại một số điểm cũng tăng lên, vì vậy điều quan trọng là phải có nhiều bản sao giống hệt nhau đáng tin cậy của cùng một dữ liệu, mỗi bản được lưu trữ trên một máy chủ khác nhau. Thật vậy, với lượng dữ liệu khổng lồ hiện đang được xử lý, lỗi hệ thống được coi là không thể tránh khỏi và do đó, các cách đối phó với điều này được tích hợp vào các phương pháp lưu trữ. Vậy nhu cầu về tốc độ và độ tin cậy được đáp ứng như thế nào?
Hệ thống tệp phân tán Hadoop
Hệ thống tệp phân tán (distributed file system DFS) cung cấp lưu trữ hiệu quả và đáng tin cậy cho dữ liệu lớn trên nhiều máy tính. Bị ảnh hưởng bởi những ý tưởng được Google công bố vào tháng 10 năm 2003 trong một bài báo nghiên cứu ra mắt Hệ thống tệp của Google, Doug Cutting, người lúc đó đang làm việc tại Yahoo, và đồng nghiệp Mike Cafarella, một sinh viên tốt nghiệp tại Đại học Washington, đã làm việc để phát triển Hadoop DFS. Hadoop, một trong những DFS phổ biến nhất, là một phần của dự án phần mềm nguồn mở lớn hơn được gọi là Hệ sinh thái Hadoop. Được đặt theo tên của một con voi đồ chơi mềm màu vàng của con trai Cutting, Hadoop được viết bằng ngôn ngữ lập trình phổ biến, Java. Ví dụ: nếu bạn sử dụng Facebook, Twitter hoặc eBay, Hadoop sẽ hoạt động ở chế độ nền trong khi bạn làm như vậy. Nó cho phép lưu trữ cả dữ liệu bán cấu trúc và phi cấu trúc và cung cấp một nền tảng để phân tích dữ liệu.
Khi chúng ta sử dụng Hadoop DFS, dữ liệu được phân phối trên nhiều nút, thường là hàng chục nghìn nút, nằm thực tế trong các trung tâm dữ liệu trên khắp thế giới. Hình 4 cho thấy cấu trúc cơ bản của một cụm Hadoop DFS duy nhất, bao gồm một NameNode chính và nhiều DataNode phụ.
NameNode xử lý tất cả các yêu cầu đến từ máy khách; Nó phân phối không gian lưu trữ và theo dõi tính khả dụng của bộ nhớ và vị trí dữ liệu. Nó cũng quản lý tất cả các hoạt động tệp cơ bản (ví dụ: mở và đóng tệp) và kiểm soát quyền truy cập dữ liệu của máy khách. DataNode chịu trách nhiệm thực sự lưu trữ dữ liệu và để làm như vậy, tạo, xóa và sao chép các khối khi cần thiết.
Sao chép dữ liệu là một tính năng thiết yếu của Hadoop DFS. Ví dụ, nhìn vào Hình 4, chúng ta thấy rằng Khối A được lưu trữ trong cả DataNode 1 và DataNode 2. Điều quan trọng là một số bản sao của mỗi khối được lưu trữ để nếu một DataNode bị lỗi, các nút khác có thể tiếp quản và tiếp tục các tác vụ xử lý mà không làm mất dữ liệu. Để theo dõi DataNode nào, nếu có, đã bị lỗi, NameNode nhận được một thông báo từ mỗi DataNode, được gọi là Heartbeat, cứ sau ba giây và nếu không nhận được tin nhắn nào thì giả định rằng DataNode được đề cập đã ngừng hoạt động. Vì vậy, nếu DataNode 1 không gửi được Heartbeat, DataNode 2 sẽ trở thành nút làm việc cho các hoạt động của Block A. Tình hình sẽ khác nếu NameNode bị mất, trong trường hợp đó cần sử dụng hệ thống sao lưu có sẵn.
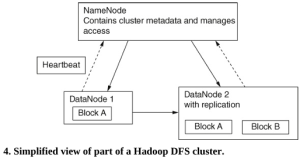
Dữ liệu chỉ được ghi vào DataNode một lần nhưng sẽ được ứng dụng đọc nhiều lần. Mỗi khối thường chỉ có 64 Mb nên có rất nhiều. Một trong những chức năng của NameNode là xác định DataNode tốt nhất để sử dụng với mức sử dụng hiện tại, đảm bảo truy cập và xử lý dữ liệu nhanh chóng. Sau đó, máy tính khách truy cập khối dữ liệu từ nút đã chọn. DataNode được thêm vào khi yêu cầu lưu trữ tăng lên, một tính năng được gọi là khả năng mở rộng/ scalability theo chiều ngang.
Một trong những lợi thế chính của Hadoop DFS so với cơ sở dữ liệu quan hệ là bạn có thể thu thập một lượng lớn dữ liệu, tiếp tục thêm vào đó và tại thời điểm đó, bạn chưa có bất kỳ ý tưởng rõ ràng nào về việc bạn muốn sử dụng nó để làm gì. Ví dụ, Facebook sử dụng Hadoop để lưu trữ lượng dữ liệu liên tục tăng lên. Không có dữ liệu nào bị mất, vì nó sẽ lưu trữ bất cứ thứ gì và mọi thứ ở định dạng ban đầu. Thêm DataNode theo yêu cầu rất rẻ và không yêu cầu thay đổi các nút hiện có. Nếu các nút trước đó trở nên dư thừa, rất dễ để ngăn chúng hoạt động. Như chúng ta đã thấy, dữ liệu có cấu trúc với các hàng và cột có thể nhận dạng có thể dễ dàng được lưu trữ trong RDBMS trong khi dữ liệu phi cấu trúc có thể được lưu trữ với giá rẻ và dễ dàng bằng cách sử dụng DFS.
Cơ sở dữ liệu NoSQL cho dữ liệu lớn
NoSQL là tên chung được sử dụng để chỉ cơ sở dữ liệu phi quan hệ và là viết tắt của Không chỉ SQL. Tại sao cần một mô hình phi quan hệ không sử dụng SQL? Câu trả lời ngắn gọn là mô hình phi quan hệ cho phép chúng ta liên tục thêm dữ liệu mới. Mô hình phi quan hệ có một số tính năng cần thiết trong việc quản lý dữ liệu lớn, cụ thể là khả năng mở rộng, tính khả dụng và hiệu suất. Với cơ sở dữ liệu quan hệ, bạn không thể tiếp tục mở rộng theo chiều dọc mà không làm mất chức năng, trong khi với NoSQL, bạn mở rộng theo chiều ngang và điều này cho phép duy trì hiệu ứng. Trước khi mô tả cơ sở hạ tầng cơ sở dữ liệu phân tán NoSQL và tại sao nó phù hợp với dữ liệu lớn, chúng ta cần xem xét Định lý CAP.
Định lý CAP
Năm 2000, Eric Brewer, giáo sư khoa học máy tính tại Đại học California Berkeley, đã trình bày Định lý CAP (tính nhất quán, tính khả dụng và dung sai phân vùng). Trong bối cảnh của hệ thống cơ sở dữ liệu phân tán, tính nhất quán đề cập đến yêu cầu rằng tất cả các bản sao của dữ liệu phải giống nhau giữa các nút. Vì vậy, trong Hình 4, ví dụ, Khối A trong DataNode 1 phải giống với Khối A trong DataNode 2. Tính khả dụng yêu cầu rằng nếu một nút bị lỗi, các nút khác vẫn hoạt động — nếu DataNode 1 bị lỗi, thì DataNode 2 vẫn phải hoạt động. Dữ liệu, và do đó DataNode, được phân phối trên các máy chủ riêng biệt về mặt vật lý và giao tiếp giữa các máy này đôi khi sẽ thất bại. Khi điều này xảy ra, nó được gọi là phân mảnh mạng/ network partition. Dung sai phân mảnh yêu cầu hệ thống tiếp tục hoạt động ngay cả khi điều này xảy ra.
Về bản chất, những gì Định lý CAP nói là đối với bất kỳ hệ thống máy tính phân tán nào, nơi dữ liệu được chia sẻ, chỉ có thể đáp ứng hai trong số ba tiêu chí này. Do đó, có ba khả năng; Hệ thống phải: nhất quán và có sẵn, nhất quán và chịu được phân mảnh, hoặc phân mảnh chịu được và có sẵn. Lưu ý rằng vì trong RDMS, mạng không được phân mảnh, nên chỉ có tính nhất quán và tính khả dụng mới được quan tâm và mô hình RDMS đáp ứng cả hai tiêu chí này. Trong NoSQL, vì chúng ta nhất thiết phải phân mảnh, chúng ta phải lựa chọn giữa tính nhất quán và tính khả dụng. Bằng cách hy sinh tính khả dụng, chúng ta có thể đợi cho đến khi đạt được tính nhất quán. Thay vào đó, nếu chúng ta chọn hy sinh tính nhất quán, đôi khi dữ liệu sẽ khác nhau giữa các máy chủ.
Từ viết tắt sắp đặt BASE (Về cơ bản có sẵn, mềm hay linh hoạt và cuối cùng nhất quán/ Basically Available, Soft, and Eventually consistent) được sử dụng như một cách thuận tiện để mô tả tình huống này. BASE dường như đã được chọn trái ngược với các thuộc tính ACID của cơ sở dữ liệu quan hệ. ‘Mềm’ trong ngữ cảnh này đề cập đến tính linh hoạt trong yêu cầu nhất quán. Mục đích không phải là từ bỏ bất kỳ tiêu chí nào trong số này mà là tìm cách tối ưu hóa cả ba, về cơ bản là một sự thỏa hiệp.
Kiến trúc của cơ sở dữ liệu NoSQL
Cái tên NoSQL bắt nguồn từ thực tế là SQL không thể được sử dụng để truy vấn các cơ sở dữ liệu này. Vì vậy, ví dụ, các mối nối như chúng ta đã thấy trong Hình 4 là không thể. Có bốn loại cơ sở dữ liệu phi quan hệ hoặc NoSQL chính: khóa-giá trị, dựa trên cột, tài liệu và đồ thị — tất cả đều hữu ích để lưu trữ một lượng lớn dữ liệu có cấu trúc và bán cấu trúc. Đơn giản nhất là cơ sở dữ liệu khóa-giá trị, bao gồm một mã định danh (khóa) và dữ liệu được liên kết với khóa đó (giá trị) như trong Hình 5. Lưu ý rằng ‘giá trị’ có thể chứa nhiều mục dữ liệu.

Tất nhiên, sẽ có nhiều cặp khóa-giá trị như vậy và việc thêm các cặp mới hoặc xóa các cặp cũ là đủ đơn giản, làm cho cơ sở dữ liệu có khả năng cao để mở rộng theo chiều ngang. Khả năng chính là chúng ta có thể tra cứu giá trị cho một khóa nhất định. Ví dụ: sử dụng phím ‘Jane Smith’, chúng tôi có thể tìm thấy địa chỉ của cô ấy. Với lượng dữ liệu khổng lồ, điều này cung cấp một giải pháp lưu trữ nhanh chóng, đáng tin cậy và dễ dàng mở rộng nhưng nó bị hạn chế bởi không có ngôn ngữ truy vấn. Cơ sở dữ liệu dựa trên cột và tài liệu là phần mở rộng của mô hình khóa-giá trị.
Cơ sở dữ liệu đồ thị theo một mô hình khác và phổ biến với các trang mạng xã hội cũng như hữu ích trong các ứng dụng kinh doanh. Các biểu đồ này thường rất lớn, đặc biệt là khi được sử dụng bởi các trang mạng xã hội. Trong loại cơ sở dữ liệu này, thông tin được lưu trữ trong các nút (tức là đỉnh) và cạnh. Ví dụ, biểu đồ trong Hình 6 cho thấy năm nút với các mũi tên giữa chúng đại diện cho các mối quan hệ. Thêm, cập nhật hoặc xóa các nút sẽ thay đổi biểu đồ.
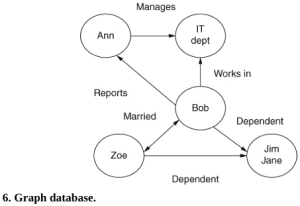
Trong ví dụ này, các nút là tên hoặc bộ phận và các cạnh là mối quan hệ giữa chúng. Dữ liệu được truy xuất từ biểu đồ bằng cách nhìn vào các cạnh. Vì vậy, ví dụ, nếu tôi muốn tìm ‘tên của các nhân viên trong bộ phận CNTT có con phụ thuộc’, tôi thấy rằng Bob đáp ứng cả hai tiêu chí. Lưu ý rằng đây không phải là một biểu đồ có hướng – chúng tôi không đi theo các mũi tên, chúng tôi tìm kiếm các liên kết.
Hiện tại, một cách tiếp cận được gọi là NewSQL đang tìm kiếm một thị trường ngách. Bằng cách kết hợp hiệu suất của cơ sở dữ liệu NoSQL và các thuộc tính ACID của mô hình quan hệ, mục đích của công nghệ tiềm ẩn này là giải quyết các vấn đề về khả năng mở rộng liên quan đến mô hình quan hệ, làm cho nó dễ sử dụng hơn cho dữ liệu lớn.
Lưu trữ đám mây
Giống như rất nhiều thuật ngữ điện toán hiện đại, Đám mây/ Cloud nghe có vẻ thân thiện, thoải mái, mời gọi và quen thuộc, nhưng thực sự ‘Đám mây’, như đã đề cập trước đó, chỉ là một cách để chỉ một mạng lưới các máy chủ được kết nối với nhau được đặt trong các trung tâm dữ liệu trên toàn thế giới. Các trung tâm dữ liệu này cung cấp một trung tâm để lưu trữ dữ liệu lớn.
Thông qua Internet, chúng tôi chia sẻ việc sử dụng các máy chủ từ xa này, được cung cấp (trên Thông qua Internet, chúng tôi chia sẻ việc sử dụng các máy chủ từ xa này, được cung cấp (khi thanh toán phí) bởi các công ty khác nhau, để lưu trữ và quản lý tệp của chúng tôi, để chạy ứng dụng, v.v. Miễn là máy tính hoặc thiết bị khác của bạn có phần mềm cần thiết để truy cập Đám mây, bạn có thể xem các tệp của mình từ bất cứ đâu và cấp quyền cho người khác làm như vậy. Bạn cũng có thể sử dụng phần mềm ‘cư trú’ trên Đám mây thay vì trên máy tính của mình. Vì vậy, nó không chỉ là vấn đề truy cập Internet mà còn là vấn đề có phương tiện để lưu trữ và xử lý thông tin – do đó thuật ngữ ‘Điện toán đám mây’. Nhu cầu lưu trữ đám mây cá nhân của chúng tôi không lớn lắm, nhưng việc mở rộng quy mô lượng thông tin được lưu trữ là rất lớn.
Amazon là nhà cung cấp dịch vụ đám mây lớn nhất nhưng lượng dữ liệu do họ quản lý là một bí mật thương mại. Chúng ta có thể hiểu được tầm quan trọng của chúng trong điện toán đám mây bằng cách xem xét một sự cố xảy ra vào tháng 2 năm 2017 khi hệ thống lưu trữ đám mây của Amazon Web Services, S3, bị ngừng hoạt động lớn (tức là dịch vụ bị mất). Điều này kéo dài khoảng năm giờ và dẫn đến mất kết nối với nhiều trang web và dịch vụ, bao gồm Netflix, Expedia và Ủy ban Chứng khoán và Giao dịch Hoa Kỳ. Amazon sau đó đã báo cáo lỗi là do con người, nói rằng một trong những nhân viên của họ đã chịu trách nhiệm về việc vô tình ngoại tuyến máy chủ. Việc khởi động lại các hệ thống lớn này mất nhiều thời gian hơn dự kiến nhưng cuối cùng đã hoàn thành thành công. Mặc dù vậy, vụ việc làm nổi bật tính nhạy cảm của Internet đối với sự ngưng hoạt động, cho dù là do một sai lầm thực sự hay do hack có chủ ý xấu.
Nén không mất dữ liệu
Vào năm 2017, Tập đoàn Dữ liệu Quốc tế (IDC) có uy tín rộng rãi ước tính rằng vũ trụ kỹ thuật số có tổng cộng 16 zettabyte (Zb) khổng lồ, tương đương với 16 x 1021 byte không thể đo lường được. Cuối cùng, khi vũ trụ kỹ thuật số tiếp tục phát triển, các câu hỏi liên quan đến dữ liệu nào chúng ta thực sự nên lưu, bao nhiêu bản sao nên được lưu giữ và trong bao lâu sẽ phải được giải quyết. Thay vào đó, nó thách thức lý do tồn tại của dữ liệu lớn để xem xét việc thanh lọc các kho dữ liệu một cách thường xuyên hoặc thậm chí lưu trữ chúng, vì bản thân điều này rất tốn kém và dữ liệu có khả năng có giá trị có thể bị mất do chúng ta không nhất thiết phải biết dữ liệu nào có thể quan trọng đối với chúng ta trong tương lai. Tuy nhiên, với lượng dữ liệu khổng lồ được lưu trữ, việc nén dữ liệu đã trở nên cần thiết để tối đa hóa không gian lưu trữ.
Có sự thay đổi đáng kể về chất lượng của dữ liệu được thu thập bằng điện tử và vì vậy trước khi có thể phân tích hữu ích, nó phải được xử lý trước để kiểm tra và khắc phục các vấn đề về tính nhất quán, lặp lại và độ tin cậy. Tính nhất quán rõ ràng là quan trọng nếu chúng ta dựa vào thông tin được trích xuất từ dữ liệu. Loại bỏ các sự lặp lại không mong muốn là cách giữ nhà tốt cho bất kỳ bộ dữ liệu nào, nhưng với các bộ dữ liệu lớn, có thêm mối lo ngại là có thể không có đủ dung lượng lưu trữ để giữ tất cả dữ liệu. Dữ liệu được nén để giảm dư thừa trong video và hình ảnh, do đó giảm yêu cầu lưu trữ và trong trường hợp video, để cải thiện tốc độ phát trực tuyến.
Có hai loại nén chính — không mất dữ liệu và mất dữ liệu. Trong nén không mất dữ liệu, tất cả dữ liệu được bảo toàn và vì vậy điều này đặc biệt hữu ích cho văn bản. Ví dụ: các tệp có phần mở rộng ‘. ZIP’, đã được nén mà không mất thông tin để giải nén chúng sẽ đưa chúng ta trở lại tệp gốc. Nếu chúng ta nén chuỗi ký tự ‘aaaaabbbbbbbbbb’ thành ‘5a10b’, thật dễ dàng để thấy cách giải nén và đi đến chuỗi ban đầu. Có nhiều thuật toán để nén nhưng trước tiên sẽ hữu ích khi xem xét cách dữ liệu được lưu trữ mà không cần nén.
ASCII (Mã tiêu chuẩn Mỹ về trao đổi thông tin) là cách mã hóa dữ liệu tiêu chuẩn để có thể lưu trữ dữ liệu trong máy tính. Mỗi ký tự được chỉ định là một số thập phân, mã ASCII của nó. Như chúng ta đã thấy, dữ liệu được lưu trữ dưới dạng chuỗi số 0 và 1. Các chữ số nhị phân này được gọi là bit. ASCII tiêu chuẩn sử dụng 8 bit (cũng được định nghĩa là 1 byte) để lưu trữ mỗi ký tự. Ví dụ: trong ASCII, chữ ‘a’ được ký hiệu bằng số thập phân 97 chuyển đổi thành 01100001 trong nhị phân. Các giá trị này được tra cứu trong bảng ASCII tiêu chuẩn, một phần nhỏ trong số đó được đưa ra ở cuối cuốn sách. Các chữ cái viết hoa có các mã ASCII khác nhau.
Hãy xem xét chuỗi ký tự ‘đã thêm’ được hiển thị được mã hóa trong Hình 7.
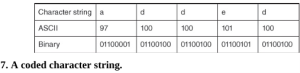
Vì vậy, ‘thêm’ chiếm 5 byte hoặc bit dung lượng lưu trữ. Cho Hình 7, giải mã được thực hiện bằng cách sử dụng bảng mã ASCII. Đây không phải là một cách tiết kiệm để mã hóa và lưu trữ dữ liệu; 8 bit mỗi ký tự có vẻ quá mức và không có tính đến thực tế là trong các tài liệu văn bản, một số chữ cái được sử dụng thường xuyên hơn nhiều so với những chữ cái khác. Có nhiều mô hình nén dữ liệu không mất dữ liệu, chẳng hạn như thuật toán Huffman, sử dụng ít dung lượng lưu trữ hơn bằng cách mã hóa độ dài thay đổi, một kỹ thuật dựa trên tần suất xuất hiện của một chữ cái cụ thể. Những chữ cái có xuất hiện cao nhất được cho mã ngắn hơn.
Lấy chuỗi ‘added’ một lần nữa, chúng ta lưu ý rằng ‘a’ xuất hiện một lần, ‘e’ xuất hiện một lần và ‘d’ xuất hiện ba lần. Vì ‘d’ xuất hiện thường xuyên nhất, nó nên được gán mã ngắn nhất. Để tìm mã Huffman cho mỗi chữ cái, chúng tôi đếm các chữ cái ‘thêm’ như sau: 1a→1e→3d
Tiếp theo, chúng ta tìm thấy hai chữ cái ít xuất hiện nhất, cụ thể là ‘a’ và ‘e’, và chúng ta tạo thành cấu trúc trong Hình 8, được gọi là cây nhị phân. Số 2 ở đầu cây được tìm thấy bằng cách cộng số lần xuất hiện của hai chữ cái ít thường xuyên nhất.
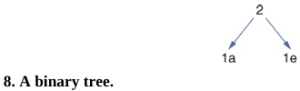
Trong Hình 9, chúng ta cho thấy nút mới đại diện cho ba lần xuất hiện của chữ ‘d’.

Hình 9 cho thấy cây đã hoàn thành với tổng số chữ cái xuất hiện ở trên cùng. Mỗi cạnh của cây được mã hóa là 0 hoặc 1, như trong Hình 10 và các mã được tìm thấy bằng cách đi theo các đường dẫn lên cây.
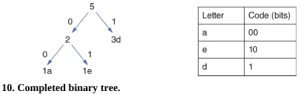
Vì vậy, ‘added’ được mã hóa là a=00; d=1; d=1; e=10; d=1, cho chúng ta 0011101. Sử dụng phương pháp này, chúng ta thấy rằng 3 bit được sử dụng để lưu trữ chữ ‘d’, 2 bit cho chữ ‘a’ và 2 bit cho chữ ‘e’, cho tổng cộng 7 bit. Đây là một cải tiến lớn so với 40 bit ban đầu.
Một cách để đo lường hiệu quả của nén là sử dụng tỷ lệ nén dữ liệu, được định nghĩa là kích thước không nén của tệp chia cho kích thước nén của nó. Trong ví dụ này, 45/7 xấp xỉ bằng 6.43, tốc độ nén cao, cho thấy tiết kiệm dung lượng lưu trữ tốt. Trong thực tế, những cây này rất lớn và được tối ưu hóa bằng cách sử dụng các kỹ thuật toán học phức tạp. Ví dụ này đã chỉ ra cách chúng ta có thể nén dữ liệu mà không làm mất bất kỳ thông tin nào có trong tệp gốc và do đó nó được gọi là nén không mất dữ liệu.
Nén mất dữ liệu
Để so sánh, các tệp âm thanh và hình ảnh thường lớn hơn nhiều so với các tệp văn bản và vì vậy một kỹ thuật khác được gọi là nén mất dữ liệu được sử dụng. Điều này là do, khi chúng ta xử lý âm thanh và hình ảnh, các phương pháp nén không mất dữ liệu có thể đơn giản là không dẫn đến tỷ lệ nén đủ cao để lưu trữ dữ liệu khả thi. Tương tự, một số mất dữ liệu có thể chấp nhận được đối với âm thanh và hình ảnh. Nén mất dữ liệu khai thác tính năng thứ hai này bằng cách xóa vĩnh viễn một số dữ liệu trong tệp gốc để giảm dung lượng lưu trữ cần thiết. Ý tưởng cơ bản là loại bỏ một số chi tiết mà không ảnh hưởng quá mức đến nhận thức của chúng ta về hình ảnh hoặc âm thanh.
Ví dụ, hãy xem xét một bức ảnh đen trắng, được mô tả chính xác hơn là hình ảnh thang độ xám, về một đứa trẻ đang ăn kem bên bờ biển. Nén mất dữ liệu loại bỏ một lượng dữ liệu bằng nhau từ hình ảnh của đứa trẻ và hình ảnh của biển. Tỷ lệ phần trăm dữ liệu bị xóa được tính toán sao cho nó sẽ không có tác động đáng kể đến nhận thức của người xem về hình ảnh kết quả (nén) — nén quá nhiều sẽ dẫn đến ảnh mờ. Có một sự đánh đổi giữa mức độ nén và chất lượng hình ảnh.
Nếu chúng ta muốn nén một hình ảnh thang độ xám, trước tiên chúng ta chia nó thành các khối 8 pixel x 8 pixel. Vì đây là một khu vực rất nhỏ, tất cả các pixel thường có tông màu tương tự nhau. Quan sát này, cùng với kiến thức về cách chúng ta cảm nhận hình ảnh, là nền tảng để nén mất dữ liệu. Mỗi pixel có một giá trị số tương ứng giữa 0 cho màu đen thuần túy và 255 cho màu trắng tinh khiết, với các số giữa các sắc thái đại diện cho màu xám. Sau khi xử lý thêm bằng cách sử dụng một phương pháp gọi là Thuật toán Cosin rời rạc, một giá trị cường độ trung bình cho mỗi khối được tìm thấy và kết quả so sánh với từng giá trị thực tế trong một khối nhất định. Vì chúng ta đang so sánh các giá trị thực tế này với giá trị trung bình, hầu hết chúng sẽ là 0 hoặc 0 khi được làm tròn. Thuật toán mất dữ liệu của chúng ta thu thập tất cả các số 0 này lại với nhau, đại diện cho thông tin từ các pixel ít quan trọng hơn đối với hình ảnh. Các giá trị này, tương ứng với tần số cao trong hình ảnh của chúng ta, tất cả đều được nhóm lại với nhau và thông tin dư thừa được loại bỏ, sử dụng một kỹ thuật gọi là lượng tử hóa, dẫn đến nén. Ví dụ: nếu trong số sáu mươi bốn giá trị, mỗi giá trị yêu cầu 1 byte dung lượng lưu trữ, chúng ta có hai mươi số 0, thì sau khi nén, chúng ta chỉ cần 45 byte dung lượng lưu trữ. Quá trình này được lặp lại cho tất cả các khối tạo nên hình ảnh và do đó thông tin dư thừa được loại bỏ trên toàn bộ.
Ví dụ, đối với hình ảnh màu, thuật toán JPEG (Nhóm chuyên gia nhiếp ảnh chung) nhận dạng màu đỏ, xanh lam và xanh lá cây, và gán mỗi hình ảnh một trọng lượng khác nhau dựa trên các đặc tính đã biết của nhận thức thị giác của con người. Màu xanh lá cây có trọng lượng lớn nhất vì mắt người nhận thức được màu xanh lá cây hơn là màu đỏ hoặc xanh lam. Mỗi pixel trong hình ảnh màu được gán trọng số màu đỏ, xanh lam và xanh lá cây, được biểu thị dưới dạng bộ ba <R,G,B>. Vì lý do kỹ thuật, bộ ba <R, G, B> thường được chuyển đổi thành bộ ba khác, <YCbCr> trong đó Y đại diện cho cường độ của màu và cả Cb và Cr đều là giá trị sắc độ, mô tả màu thực tế. Sử dụng một thuật toán toán học phức tạp, có thể giảm giá trị của mỗi pixel và cuối cùng đạt được nén mất dữ liệu bằng cách giảm giá trị của mỗi pixel và cuối cùng đạt được nén mất dữ liệu bằng cách giảm số lượng pixel được lưu.
Các tệp đa phương tiện nói chung, do kích thước của chúng, được nén bằng các phương pháp mất dữ liệu. Tệp càng nén thì chất lượng tái tạo càng kém, nhưng vì một số dữ liệu bị hy sinh, có thể đạt được tỷ lệ nén lớn hơn, làm cho tệp nhỏ hơn.
Theo tiêu chuẩn quốc tế về nén hình ảnh được sản xuất lần đầu tiên vào năm 1992 bởi JPEG, định dạng tệp JPEG cung cấp phương pháp phổ biến nhất để nén cả ảnh màu và thang độ xám. Nhóm này vẫn rất tích cực và gặp nhau vài lần trong năm.
Hãy xem xét lại ví dụ về một bức ảnh đen trắng của một đứa trẻ đang ăn kem bên bờ biển. Lý tưởng nhất là khi chúng ta nén hình ảnh này, chúng ta muốn phần có hình trẻ em vẫn sắc nét, vì vậy để đạt được điều này, chúng ta sẵn sàng hy sinh một số độ rõ nét trong các chi tiết hậu cảnh. Một phương pháp mới, được gọi là nén cong dữ liệu, được phát triển bởi các nhà nghiên cứu tại Trường Kỹ thuật và Khoa học Ứng dụng Henry Samueli, UCLA, hiện đã làm cho điều này trở nên khả thi. Những độc giả quan tâm đến các chi tiết được tham khảo phần Đọc thêm ở cuối cuốn sách.
Chúng ta đã thấy cách một hệ thống tệp dữ liệu phân tán có thể được sử dụng để lưu trữ dữ liệu lớn. Các vấn đề về lưu trữ đã được khắc phục đến mức các nguồn dữ liệu lớn hiện có thể được sử dụng để trả lời các câu hỏi mà trước đây chúng ta không thể trả lời. Như chúng ta sẽ thấy trong Chương 4, một phương pháp thuật toán được gọi là MapReduce được sử dụng để xử lý dữ liệu được lưu trữ trong Hadoop DFS.
Đọc thêm
- J. Date, An Introduction to Database Systems (8th edn; Pearson, 2003).
Guy Harrison, Next Generation Databases: NoSQL and Big Data (Springer, 2015).
Chương 4 Phân tích dữ liệu lớn
Sau khi thảo luận về cách dữ liệu lớn được thu thập và lưu trữ, giờ đây chúng ta có thể xem xét một số kỹ thuật được sử dụng để khám phá thông tin hữu ích từ dữ liệu đó như sở thích của khách hàng hoặc dịch bệnh đang lây lan nhanh như thế nào. Phân tích dữ liệu lớn, thuật ngữ tổng hợp cho các kỹ thuật này, đang thay đổi nhanh chóng khi kích thước của bộ dữ liệu tăng lên và thống kê cổ điển nhường chỗ cho mô hình mới này.
Hadoop, được giới thiệu trong Chương 3, cung cấp một phương tiện để lưu trữ dữ liệu lớn thông qua hệ thống tệp phân tán của nó. Như một ví dụ về phân tích dữ liệu lớn, chúng ta sẽ xem xét MapReduce, là một hệ thống xử lý dữ liệu phân tán và tạo thành một phần của chức năng cốt lõi của Hệ sinh thái Hadoop. Amazon, Google, Facebook và nhiều tổ chức khác sử dụng Hadoop để lưu trữ và xử lý dữ liệu của họ.
Giảm ánh xạ/ MapReduce
Một cách phổ biến để xử lý dữ liệu lớn là chia nó thành các phần nhỏ và sau đó xử lý từng phần riêng lẻ, về cơ bản là những gì MapReduce làm là phân tán các phép tính hoặc truy vấn cần thiết trên nhiều, nhiều máy tính. Rất đáng để làm việc thông qua một ví dụ được đơn giản hóa và rút gọn về cách thức hoạt động của MapReduce – và khi chúng ta đang làm điều này bằng tay, nó thực sự sẽ chỉ là một ví dụ được giản lược đáng kể, nhưng nó vẫn sẽ chứng minh quy trình sẽ được sử dụng cho dữ liệu lớn. Thông thường sẽ có hàng nghìn bộ xử lý được sử dụng để xử lý một lượng lớn dữ liệu song song, nhưng quy trình này có thể mở rộng và nó thực sự là một ý tưởng rất khéo léo và đơn giản để làm theo.
Có một số bước trong mô hình phân tích này: bước ánh xạ; bước duyệt/ shuffle; và bước giảm trừ. Bước ánh xạ được viết bởi người dùng và sắp xếp dữ liệu mà chúng ta quan tâm. Bước duyệt, là một phần của mã Hadoop MapReduce chính, sau đó nhóm dữ liệu theo khóa, và cuối cùng chúng ta có thành phần giảm trừ, một lần nữa được cung cấp bởi người dùng, tổng hợp các nhóm này và tạo ra kết quả. Kết quả sau đó được gửi đến HDFS để lưu trữ.
Ví dụ, giả sử chúng ta có các tệp khóa-giá trị sau được lưu trữ trong hệ thống tệp phân tán Hadoop, với số liệu thống kê về từng điều sau: sởi, virus Zika, TB và Ebola. Bệnh là chìa khóa và một giá trị đại diện cho số ca bệnh cho mỗi bệnh được đưa ra. Chúng ta quan tâm đến tổng số ca của từng bệnh.
Tệp 1: Sởi:3 Zika:2 TB:1 Sởi,1 Zika:3 Ebola:2
Tệp 2: Sởi:4 Zika:2 TB:1
Tệp 3: Sởi:3 Zika:2 Sởi:4 Zika:1 Ebola:3
Trình lập ánh xạ cho phép chúng ta đọc từng tệp đầu vào này một cách riêng biệt, từng dòng một, như trong Hình 11. Sau đó, trình lập ánh xạ trả về các cặp khóa-giá trị cho mỗi dòng riêng biệt này.
Sau khi tách các tệp và tìm thấy giá trị khóa cho mỗi lần tách, bước tiếp theo trong thuật toán được cung cấp bởi chương trình chính/ master, chương trình này sắp xếp và duyệt các giá trị khóa. Các bệnh được sắp xếp theo thứ tự bảng chữ cái và kết quả được gửi đến một tệp thích hợp sẵn sàng cho bộ giảm trừ, như trong Hình 12.
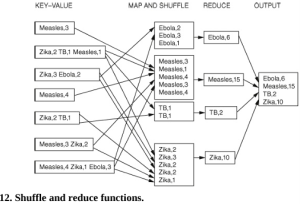
Tiếp tục làm theo Hình 12, thành phần giảm kết hợp kết quả của các giai đoạn bản đồ và xáo trộn, và kết quả là gửi từng bệnh đến một tệp riêng biệt. Bước giảm trong thuật toán sau đó cho phép tính toán tổng số riêng lẻ và các kết quả này được gửi đến tệp đầu ra cuối cùng, dưới dạng cặp khóa-giá trị, có thể được lưu trong DFS.
Đây là một ví dụ rất nhỏ, nhưng phương pháp MapReduce cho phép chúng ta phân tích lượng dữ liệu rất lớn. Ví dụ, sử dụng dữ liệu được cung cấp bởi Common Crawl, một tổ chức phi lợi nhuận cung cấp một bản sao miễn phí của Internet, chúng ta có thể đếm số lần mỗi từ xuất hiện trên Internet bằng cách viết một chương trình máy tính phù hợp sử dụng MapReduce.
Bộ lọc Bloom/ bộ lọc Tính nổi bật
Một phương pháp đặc biệt hữu ích để khai thác dữ liệu lớn là bộ lọc Bloom, một kỹ thuật dựa trên lý thuyết xác suất được phát triển vào những năm 1970. Như chúng ta sẽ thấy, bộ lọc Bloom đặc biệt phù hợp với các ứng dụng có vấn đề về lưu trữ và dữ liệu có thể được coi là một danh sách.
Ý tưởng cơ bản đằng sau bộ lọc Bloom là chúng ta muốn xây dựng một hệ thống, dựa trên danh sách các yếu tố dữ liệu, để trả lời câu hỏi ‘X có trong danh sách không?’ Với các bộ dữ liệu lớn, việc tìm kiếm qua toàn bộ tập hợp có thể quá chậm để hữu ích, vì vậy chúng tôi sử dụng bộ lọc Bloom, là một phương pháp xác suất, không chính xác 100% — thuật toán có thể quyết định rằng một phần tử thuộc về danh sách trong khi thực tế nó không phải vậy; Nhưng nó là một phương pháp nhanh chóng, đáng tin cậy và lưu trữ hiệu quả để trích xuất kiến thức hữu ích từ dữ liệu.
Bộ lọc Bloom có nhiều ứng dụng. Ví dụ: chúng có thể được sử dụng để kiểm tra xem một địa chỉ Web cụ thể có dẫn đến một trang web độc hại hay không. Trong trường hợp này, bộ lọc Bloom sẽ hoạt động như một danh sách đen các URL độc hại đã biết để có thể kiểm tra một cách nhanh chóng và chính xác, liệu có khả năng URL bạn vừa nhấp vào có an toàn hay không. Các địa chỉ web mới được phát hiện là độc hại có thể được thêm vào danh sách đen. Vì hiện có hơn một tỷ trang web và nhiều trang web khác được thêm vào hàng ngày, việc theo dõi các trang web độc hại là một vấn đề dữ liệu lớn.
Một ví dụ liên quan là email độc hại, có thể là thư rác hoặc có thể chứa các nỗ lực lừa đảo. Bộ lọc Bloom cung cấp cho chúng ta một cách thức nhanh chóng để kiểm tra từng địa chỉ email và do đó chúng ta có thể đưa ra cảnh báo kịp thời nếu thích hợp. Mỗi địa chỉ chiếm khoảng 20 byte, vì vậy việc lưu trữ và kiểm tra từng địa chỉ trở nên tốn rất nhiều thời gian vì chúng ta cần làm điều này rất nhanh — bằng cách sử dụng bộ lọc Bloom, chúng ta có thể giảm đáng kể lượng dữ liệu được lưu trữ. Chúng ta có thể thấy điều này hoạt động như thế nào bằng cách làm theo quy trình xây dựng một bộ lọc Bloom nhỏ và cho thấy nó sẽ hoạt động như thế nào.
Giả sử chúng ta có danh sách các địa chỉ email sau đây mà chúng ta muốn gắn cờ là độc hại: <aaa@aaaa.com>; <bbb@nnnn.com>; <ccc@ff.com>; <dd@ggg.com>. Để xây dựng bộ lọc Bloom của chúng ta, trước tiên giả sử chúng ta có 10 bit bộ nhớ có sẵn trên máy tính. Đây được gọi là mảng bit và ban đầu nó trống. Một bit chỉ có hai trạng thái, thường được ký hiệu bằng 0 và 1, vì vậy chúng ta sẽ bắt đầu bằng cách đặt tất cả các giá trị trong mảng bit thành 0, có nghĩa là trống. Như chúng ta sẽ thấy ngay sau đây, một bit có giá trị là 1 sẽ có nghĩa là chỉ số liên quan đã được gán ít nhất một lần.
Kích thước của mảng bit của chúng ta là cố định và sẽ vẫn giữ nguyên bất kể chúng ta thêm bao nhiêu trường hợp. Chúng tôi lập chỉ mục từng bit trong mảng như trong Hình 13.

Bây giờ chúng ta cần giới thiệu các hàm băm/ hash functions, là các thuật toán được thiết kế để ánh xạ từng phần tử trong một danh sách nhất định đến một trong các vị trí trong mảng. Bằng cách này, bây giờ chúng ta chỉ lưu trữ vị trí được ánh xạ trong mảng, thay vì chính địa chỉ email, do đó dung lượng lưu trữ cần thiết được giảm bớt.
Đối với minh họa này, chúng ta hiển thị kết quả của việc sử dụng hai hàm băm, nhưng thông thường mười bảy hoặc mười tám hàm sẽ được sử dụng cùng với một mảng lớn hơn nhiều. Vì các hàm này được thiết kế để ánh xạ ít nhiều đồng nhất, mỗi chỉ mục có cơ hội như nhau để trở thành kết quả mỗi khi thuật toán băm được áp dụng cho một địa chỉ khác.
Vì vậy, trước tiên chúng ta để các thuật toán băm gán mỗi địa chỉ email cho một trong các chỉ mục của mảng.
Để thêm ‘aaa@aaaa.com’ vào mảng, trước tiên nó được truyền qua hàm băm 1, nó trả về chỉ mục mảng hoặc giá trị vị trí. Ví dụ: giả sử hàm băm 1 trả về chỉ mục 3. Hàm băm 2, một lần nữa được áp dụng cho ‘aaa@aaaa.com’, trả về chỉ mục 4. Hai vị trí này sẽ có giá trị bit được lưu trữ được đặt thành 1. Nếu vị trí đã được đặt thành 1 thì nó sẽ được để yên. Tương tự, việc thêm ‘bbb@nnnn.com’ có thể dẫn đến vị trí 2 và 7 bị chiếm dụng hoặc được đặt thành 1 và ‘ccc@ff.com’ có thể trả về vị trí 4 và 7. Cuối cùng, giả sử các hàm băm được áp dụng cho ‘dd@ggg.com’ trả về các vị trí 2 và 6. Những kết quả này được tóm tắt trong Hình 14.

Mảng bộ lọc Bloom thực tế được hiển thị trong Hình 15 với các vị trí chiếm dụng có giá trị được đặt thành 1.

Vì vậy, làm thế nào để chúng ta sử dụng mảng này như một bộ lọc Bloom? Giả sử, bây giờ, chúng ta nhận được một email và chúng ta muốn kiểm tra xem địa chỉ đó có xuất hiện trong danh sách địa chỉ email độc hại hay không. Giả sử nó ánh xạ đến các vị trí 2 và 7, cả hai đều có giá trị 1. Bởi vì tất cả các giá trị được trả về bằng 1, nó có thể thuộc về danh sách và do đó có thể là độc hại. Chúng tôi không thể nói chắc chắn rằng nó thuộc về danh sách vì vị trí 2 và 7 là kết quả của việc ánh xạ các địa chỉ và chỉ mục khác có thể được sử dụng nhiều lần. Vì vậy, kết quả kiểm tra một phần tử cho tư cách thành viên danh sách cũng bao gồm xác suất trả về dương tính giả. Tuy nhiên, nếu một chỉ mục mảng có giá trị 0 được trả về bởi bất kỳ hàm băm nào (và hãy nhớ rằng, thường sẽ có mười bảy hoặc mười tám hàm) thì chúng ta chắc chắn sẽ biết rằng địa chỉ không có trong danh sách.
Toán học liên quan rất phức tạp, nhưng chúng ta có thể thấy rằng mảng càng lớn thì càng có nhiều không gian trống và càng ít khả năng kết quả dương tính giả hoặc khớp nối sai. Rõ ràng kích thước của mảng sẽ được xác định bởi số lượng khóa và hàm băm được sử dụng, nhưng nó phải đủ lớn để cho phép đủ số lượng không gian trống để bộ lọc hoạt động hiệu quả và giảm thiểu số lượng dương tính giả.
Bộ lọc Bloom nhanh và chúng có thể cung cấp một cách rất hữu ích để phát hiện các giao dịch thẻ tín dụng gian lận. Bộ lọc kiểm tra xem liệu một mục cụ thể có thuộc về một danh sách hoặc tập hợp nhất định hay không, vì vậy một giao dịch bất thường sẽ được gắn cờ là không thuộc danh sách các giao dịch thông thường của bạn. Ví dụ: nếu bạn chưa bao giờ mua thiết bị leo núi trên thẻ tín dụng của mình, bộ lọc Bloom sẽ gắn cờ việc mua dây leo núi là đáng ngờ. Mặt khác, nếu bạn mua thiết bị leo núi, bộ lọc Bloom sẽ xác định giao dịch mua này có thể chấp nhận được nhưng sẽ có khả năng kết quả thực sự sai.
Bộ lọc Bloom cũng có thể được sử dụng để lọc email để tìm thư rác. Bộ lọc thư rác cung cấp một ví dụ điển hình vì chúng ta không biết chính xác những gì chúng ta đang tìm kiếm — thường chúng ta đang tìm kiếm các mẫu, vì vậy nếu chúng ta muốn các email có chứa từ ‘mouse’/chuột được coi là thư rác/ spam, chúng ta cũng muốn các biến thể như ‘m0use’ và ‘mou$e’ được coi là thư rác. Trên thực tế, chúng tôi muốn tất cả các biến thể có thể, có thể nhận dạng được của từ được xác định là thư rác. Sẽ dễ dàng hơn nhiều để lọc mọi thứ không khớp với một từ nhất định, vì vậy chúng tôi sẽ chỉ cho phép ‘mouse ‘ đi qua bộ lọc.
Bộ lọc Bloom cũng được sử dụng để tăng tốc các thuật toán được sử dụng để xếp hạng truy vấn Web, một chủ đề được quan tâm đáng kể đối với những người có trang web để quảng bá.
Xếp hạng trang/ PageRank
Khi chúng ta tìm kiếm trên Google, các trang web được trả về được xếp hạng theo mức độ liên quan của chúng với các cụm từ tìm kiếm. Google đạt được thứ tự này chủ yếu bằng cách áp dụng một thuật toán gọi là PageRank. Cái tên PageRank được cho là đã được chọn theo Larry Page, một trong những người sáng lập Google, người làm việc với người đồng sáng lập Sergey Brin, đã xuất bản các bài báo về thuật toán mới này. Cho đến mùa hè năm 2016, kết quả PageRank đã được công bố công khai bằng cách tải xuống Thanh công cụ PageRank. Công cụ PageRank công khai dựa trên phạm vi từ 1 đến 10. Trước khi nó bị rút ra, tôi đã lưu lại một vài kết quả. Nếu tôi gõ ‘Dữ liệu lớn’ vào Google bằng máy tính xách tay của mình, tôi nhận được một thông báo thông báo rằng có ‘Khoảng 370.000.000 kết quả (0,44 giây)’ với PageRank là 9. Đứng đầu danh sách này là một số quảng cáo trả phí, tiếp theo là Wikipedia. Tìm kiếm trên ‘dữ liệu’ trả về khoảng 5.530.000.000 kết quả trong 0,43 giây với PageRank là 9. Các ví dụ khác, tất cả đều có PageRank là 10, bao gồm trang web của chính phủ Hoa Kỳ, Facebook, Twitter và Hiệp hội các trường đại học châu Âu.
Phương pháp tính PageRank này dựa trên số lượng liên kết trỏ đến một trang web—càng nhiều liên kết, điểm càng cao và trang xuất hiện dưới dạng kết quả tìm kiếm càng cao. Nó không phản ánh số lần một trang được truy cập. Nếu bạn là một nhà thiết kế trang web, bạn muốn tối ưu hóa trang web của mình để nó xuất hiện rất gần đầu danh sách cho một số cụm từ tìm kiếm nhất định, vì hầu hết mọi người không nhìn xa hơn ba hoặc bốn kết quả đầu tiên. Điều này đòi hỏi một số lượng lớn các liên kết và kết quả là, gần như không thể tránh khỏi, một giao dịch liên kết đã được thiết lập. Google đã cố gắng giải quyết thứ hạng ‘nhân tạo’ này bằng cách chỉ định thứ hạng mới là 0 cho các công ty có liên quan hoặc thậm chí bằng cách xóa hoàn toàn họ khỏi Google, nhưng điều này không giải quyết được vấn đề; Việc buôn bán chỉ đơn thuần là bị ép dấu dưới gầm bàn, và các liên kết tiếp tục được bán.
Bản thân PageRank đã không bị bỏ rơi và nó tạo thành một phần của một bộ lớn các chương trình xếp hạng không có sẵn để xem công khai. Google tính toán lại thứ hạng thường xuyên để phản ánh các liên kết được thêm vào cũng như các trang web mới. Vì PageRank nhạy cảm về mặt thương mại, chi tiết đầy đủ không được công khai nhưng chúng ta có thể có ý tưởng chung bằng cách xem một ví dụ. Thuật toán cung cấp một cách phức tạp để phân tích các liên kết giữa các trang web dựa trên lý thuyết xác suất, trong đó xác suất 1 cho biết sự chắc chắn và xác suất 0 cho biết không thể, với mọi thứ khác có giá trị xác suất ở đâu đó ở giữa.
Để hiểu cách thức hoạt động của bảng xếp hạng, trước tiên chúng ta cần biết phân phối xác suất trông như thế nào. Nếu chúng ta nghĩ về kết quả của việc tung một con xúc xắc sáu mặt công bằng, mỗi kết quả từ 1 đến 6 đều có khả năng xảy ra như nhau và vì vậy mỗi kết quả có xác suất là 1/6. Danh sách tất cả các kết quả có thể xảy ra, cùng với xác suất liên quan đến mỗi kết quả, mô tả phân phối xác suất.
Quay trở lại vấn đề xếp hạng các trang web theo mức độ quan trọng, chúng ta không thể nói rằng mỗi trang web đều quan trọng như nhau, nhưng nếu chúng ta có một cách gán xác suất cho mỗi trang web, điều này sẽ cung cấp cho chúng ta một dấu hiệu hợp lý về tầm quan trọng. Vì vậy, những gì các thuật toán như PageRank làm là xây dựng một phân phối xác suất cho toàn bộ Web. Để giải thích điều này, chúng ta hãy xem xét một người lướt web ngẫu nhiên, người bắt đầu ở bất kỳ trang web nào và sau đó chuyển đến một trang khác bằng cách sử dụng các liên kết Web có sẵn.
Chúng ta sẽ xem xét một ví dụ đơn giản trong đó chúng ta có một web chỉ bao gồm ba trang web; BigData1, BigData2 và BigData3. Giả sử các liên kết duy nhất là từ BigData2 đến BigData3, BigData2 đến BigData1 và BigData1 đến BigData3. Sau đó, web của chúng ta có thể được biểu diễn như trong Hình 16, trong đó các nút là các trang web và các mũi tên (cạnh) là các liên kết.
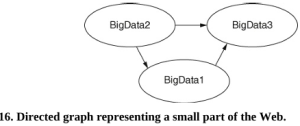
Mỗi trang có một PageRank cho biết tầm quan trọng hoặc mức độ phổ biến của nó. BigData3 sẽ được xếp hạng cao nhất vì nó có nhiều liên kết nhất đến nó, khiến nó trở nên phổ biến nhất. Giả sử bây giờ một người lướt web ngẫu nhiên truy cập một trang web, họ có một phiếu bầu tỷ lệ để bầu, được chia đều giữa các lựa chọn tiếp theo của trang web. Ví dụ: nếu người lướt web ngẫu nhiên của chúng tôi hiện đang truy cập BigData1, thì lựa chọn duy nhất là truy cập BigData3. Vì vậy, chúng ta có thể nói rằng BigData1 bỏ phiếu 1 cho BigData3.
Trong Web thực tế, các liên kết mới được tạo ra mọi lúc, vì vậy giả sử bây giờ chúng ta thấy rằng BigData3 liên kết đến BigData2, như trong Hình 17, thì PageRank cho BigData2 sẽ thay đổi vì người lướt web ngẫu nhiên bây giờ có một lựa chọn về nơi để đi sau BigData3.
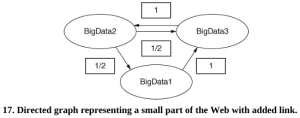
Nếu người lướt web ngẫu nhiên của chúng ta bắt đầu từ BigData1, thì lựa chọn duy nhất là truy cập BigData3 tiếp theo và do đó, tổng số phiếu bầu là 1 thuộc về BigData3 và BigData2 nhận được phiếu bầu là 0. Nếu họ bắt đầu từ BigData2, phiếu bầu được chia đều giữa BigData3 và BigData1. Cuối cùng, nếu người lướt web ngẫu nhiên bắt đầu từ BigData3, toàn bộ phiếu bầu của họ sẽ được bỏ cho BigData2. Các ‘phiếu bầu’ tỷ lệ này được tóm tắt trong Hình 18.
Sử dụng Hình 18, chúng ta thấy tổng số phiếu bầu cho mỗi trang web như sau:
Tổng số phiếu bầu cho BD1 là ½(đến từ BD2)
Tổng số phiếu bầu cho BD2 là 1 (đến từ BD3)
Tổng số phiếu bầu cho BD3 là 1½ (đến từ BD1 và BD2)
Vì lựa chọn trang bắt đầu cho người lướt là ngẫu nhiên, mỗi trang có khả năng như nhau và do đó được gán PageRank ban đầu là 1/3. Để tạo thành PageRanks mong muốn cho ví dụ của chúng ta, chúng ta cần cập nhật PageRanks ban đầu theo tỷ lệ phiếu bầu cho mỗi trang.
Ví dụ: BD1 chỉ có 1/2 phiếu bầu, do BD2 bầu, vì vậy PageRank của BD1 là 1/3×1/2=1/6. Tương tự, PageRank BD2 được đưa ra bởi 1/3×1=2/6 và PageRank BD3 là 1/3x3x2=3/6. Vì tất cả các PageRank bây giờ cộng lại thành một, chúng ta có một phân phối xác suất cho thấy tầm quan trọng hoặc thứ hạng của mỗi trang.
Nhưng có một sự phức tạp ở đây. Chúng tôi nói rằng xác suất một người lướt ngẫu nhiên có mặt trên bất kỳ trang nào ban đầu là 1/3. Sau một bước, chúng ta đã tính toán xác suất một người lướt sóng ngẫu nhiên trên BD1 là 1/6. Còn sau hai bước thì sao? Một lần nữa, chúng tôi sử dụng PageRanks hiện tại làm phiếu bầu để tính PageRanks mới. Các phép tính hơi khác nhau đối với vòng này vì PageRanks hiện tại không bằng nhau nhưng phương pháp giống nhau, đưa ra PageRank mới như sau: PageRank BD1 là 2/12, PageRank BD2 là 6/12 và PageRank BD3 là 4/12. Các bước này, hoặc lặp lại, được lặp lại cho đến khi thuật toán hội tụ, có nghĩa là quá trình tiếp tục như thế này cho đến khi không thể thực hiện thêm bất kỳ phép nhân nào nữa. Sau khi đạt được thứ hạng cuối cùng, PageRank có thể chọn trang có thứ hạng cao nhất cho một tìm kiếm nhất định.
Page và Brin, trong các bài báo nghiên cứu ban đầu của họ, đã trình bày một phương trình để tính PageRank bao gồm Hệ số giảm chấn/ Damping Factor d, được định nghĩa là xác suất mà một người lướt web ngẫu nhiên sẽ nhấp vào một trong các liên kết trên trang hiện tại. Do đó, xác suất mà một người lướt web ngẫu nhiên sẽ không nhấp vào một trong các liên kết trên trang hiện tại là , có nghĩa là người lướt web ngẫu nhiên đã hoàn thành việc lướt web. Chính Damping Factor này đã đảm bảo PageRank trung bình trên toàn bộ Web ổn định xuống còn 1, sau một số lượng đủ các phép tính lặp đi lặp lại. Page và Brin báo cáo rằng một web bao gồm 322 triệu liên kết đã ổn định sau năm mươi hai lần lặp lại.
Bộ dữ liệu công khai
Có rất nhiều bộ dữ liệu lớn có sẵn miễn phí mà các nhóm hoặc cá nhân quan tâm có thể sử dụng cho các dự án của riêng họ. Common Crawl, được đề cập trước đó trong chương này, là một ví dụ. Được lưu trữ bởi Chương trình Bộ dữ liệu Công cộng của Amazon, vào tháng 10 năm 2016, kho lưu trữ hàng tháng của Common Crawl chứa hơn 3,25 tỷ trang web. Bộ dữ liệu công khai thuộc nhiều chuyên ngành, bao gồm dữ liệu bộ gen, hình ảnh vệ tinh và dữ liệu tin tức trên toàn thế giới. Đối với những người không có khả năng viết mã của riêng họ, Ngram Viewer của Google cung cấp một cách thức thú vị để khám phá một số bộ dữ liệu lớn một cách tương tác (xem Đọc thêm để biết chi tiết).
Mô hình dữ liệu lớn
Chúng ta đã thấy một số cách mà dữ liệu lớn có thể hữu ích và trong Chương 2 chúng ta đã nói về dữ liệu nhỏ. Đối với phân tích dữ liệu nhỏ, phương pháp khoa học được thiết lập tốt và nhất thiết phải liên quan đến sự tương tác của con người: ai đó đưa ra một ý tưởng, xây dựng một giả thuyết hoặc mô hình và nghĩ ra các cách để kiểm tra các dự đoán của nó. Nhà thống kê lỗi lạc George Box đã viết vào năm 1978, “tất cả các mô hình đều sai, nhưng một số đều hữu ích”. Quan điểm của ông là các mô hình thống kê và khoa học nói chung không cung cấp các đại diện chính xác về thế giới về chúng ta, nhưng một mô hình tốt có thể cung cấp một bức tranh hữu ích để dựa trên các dự đoán và rút ra kết luận một cách tự tin. Tuy nhiên, như chúng tôi đã chỉ ra, khi làm việc với dữ liệu lớn, chúng ta không tuân theo phương pháp này. Thay vào đó, chúng ta thấy rằng máy móc, không phải nhà khoa học, chiếm ưu thế. [Nhưng máy móc là khoa học mà?]
Viết vào năm 1962, Thomas Kuhn đã mô tả khái niệm về các cuộc cách mạng khoa học, theo sau các giai đoạn dài của khoa học bình thường khi một mô hình hiện có được phát triển và nghiên cứu đầy đủ. Nếu những bất thường, đủ khó để giải quyết, xảy ra, làm suy yếu lý thuyết hiện có, dẫn đến việc các nhà nghiên cứu mất niềm tin, thì điều này được gọi là ‘khủng hoảng’, và cuối cùng nó được giải quyết bằng một lý thuyết hoặc mô hình mới. Để một mô hình mới được chấp nhận, nó phải trả lời một số câu hỏi được tìm thấy là có vấn đề trong mô hình cũ. Tuy nhiên, nhìn chung, một mô hình mới không hoàn toàn lấn át mô hình trước đó. Ví dụ, sự thay đổi từ cơ học Newton sang thuyết tương đối của Einstein đã thay đổi cách khoa học nhìn thế giới, mà không làm cho các định luật Newton trở nên lỗi thời: cơ học Newton hiện tạo thành một trường hợp đặc biệt của thuyết tương đối rộng hơn. Chuyển từ thống kê cổ điển sang phân tích dữ liệu lớn cũng thể hiện một sự thay đổi đáng kể và có nhiều dấu hiệu của sự thay đổi mô hình. Vì vậy, chắc chắn các kỹ thuật sẽ cần được phát triển để đối phó với tình hình mới này.
Hãy xem xét kỹ thuật tìm mối tương quan trong dữ liệu, cung cấp một phương tiện dự đoán dựa trên sức mạnh của mối quan hệ giữa các biến. Nó nghĩa là dự đoán dựa trên sức mạnh của mối quan hệ giữa các biến. Nó được thừa nhận trong các thống kê cổ điển rằng mối tương quan không ngụ ý nhân quả. Ví dụ, một giáo viên có thể ghi lại cả số lượng học sinh vắng mặt trong bài giảng và điểm của học sinh; và sau đó, khi tìm thấy một mối tương quan rõ ràng, họ có thể sử dụng sự vắng mặt để dự đoán điểm. Tuy nhiên, sẽ không chính xác nếu kết luận rằng vắng mặt gây ra điểm kém. Chúng ta không thể biết tại sao hai biến có mối tương quan chỉ bằng cách nhìn vào các tính toán mù: có thể những học sinh kém khả năng có xu hướng nghỉ học; có thể những sinh viên vắng mặt vì ốm đau sau này không thể bắt kịp. Sự tương tác và giải thích của con người là cần thiết để quyết định mối tương quan nào là hữu ích.
Với dữ liệu lớn, việc sử dụng tương quan tạo ra các vấn đề bổ sung. Nếu chúng ta xem xét một bộ dữ liệu khổng lồ, các thuật toán có thể được viết, mà khi được áp dụng, trả về một số lượng lớn các mối tương quan giả hoàn toàn độc lập với quan điểm, ý kiến hoặc giả thuyết của bất kỳ con người nào. Các vấn đề phát sinh với các mối tương quan sai lệch – ví dụ, tỷ lệ ly hôn và tiêu thụ bơ thực vật, đây chỉ là một trong nhiều mối tương quan giả mạo được báo cáo trên các phương tiện truyền thông. Chúng ta có thể thấy sự vô lý của mối tương quan này bằng cách áp dụng phương pháp khoa học. Tuy nhiên, khi số lượng biến trở nên lớn, số lượng tương quan giả cũng tăng lên. Đây là một trong những vấn đề chính liên quan đến việc cố gắng trích xuất thông tin hữu ích từ dữ liệu lớn, bởi vì khi làm như vậy, cũng như khai thác dữ liệu lớn, chúng ta thường tìm kiếm các mô hình và mối tương quan. Như chúng ta sẽ thấy trong Chương 5, một trong những lý do khiến Google Flu Trends thất bại trong dự đoán của mình là vì những vấn đề này.
Đọc thêm
Thomas S. Kuhn and Ian Hacking, The Structure of Scientific Revolutions: 50th Anniversary Edition (University of Chicago Press, 2012).
Bernard Marr, Big Data: Using SMART Big Data, Analytics and Metrics to Make Better Decisions and Improve Performance (Wiley, 2015).
Lars Nielson and Noreen Burlingame, A Simple Introduction to Data Science (New Street Communications, 2012).



- BS Đỗ Thị Thuý Anh